第 5 章 循环神经网络
循环神经网络(Recurrent Neural Network)是深度学习领域中一种非常经典的网络结构,在现实生活中有着广泛的应用。以槽填充(slot filling)为例,如图 5.1 所示,假设订票系统听到用户说:“我想在 6 月 1 日抵达上海。”,系统有一些槽(slot):目的地和到达时间,系统要自动知道这边的每一个单词是属于哪一个槽,比如“上海”属于目的地槽,“6 月 1 号”属于到达时间槽。
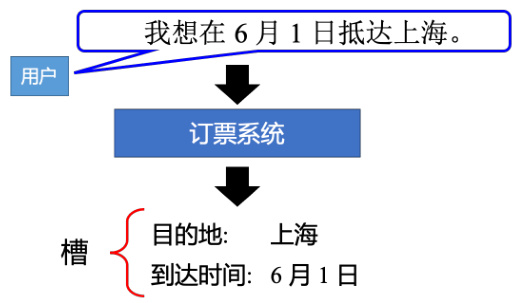
图 5.1 槽填充示例
这个问题可以使用一个前馈神经网络(feedforward neural network)来解,如图 5.2 所示,输入是一个单词,把“上海”变成一个向量,“丢”到这个神经网络里面。要把一个单词丢到一个神经网络里面去,就必须把它变成一个向量。
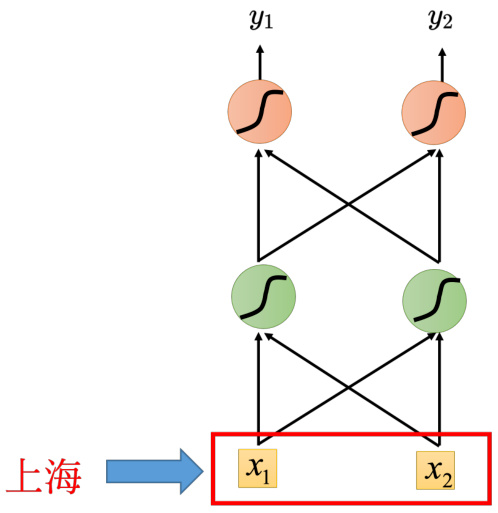
图 5.2 使用神经网络解决槽填充问题
以下是把单词用向量来表示的方法。
5.1 独热编码
假设词典中有 5 个单词:apple,bag,cat,dog,elephant,如式 (5.1)。向量的大小是词典大小。每一个维度对应词典的一个单词。对应单词的维度为 1,其他为 0。
如果只是用独热编码来描述一个单词,会有一些问题:因为很多单词可能都没有见过,所以需要在独热编码里面多加维度,用一个维度代表 other,如图 5.3(a) 所示。如果不是在词表中,有的单词就归类到 other 里面去(Pig,Cow 归类到 other 里面去)。我们可以用每一个单词的字母来表示它的向量,比如单词是 apple,apple 里面有出现 app、ple、ppl,在这个向量里面对应到 app、ple、ppl 的维度就是 1,其他都为 0,如图 5.3(b) 所示。
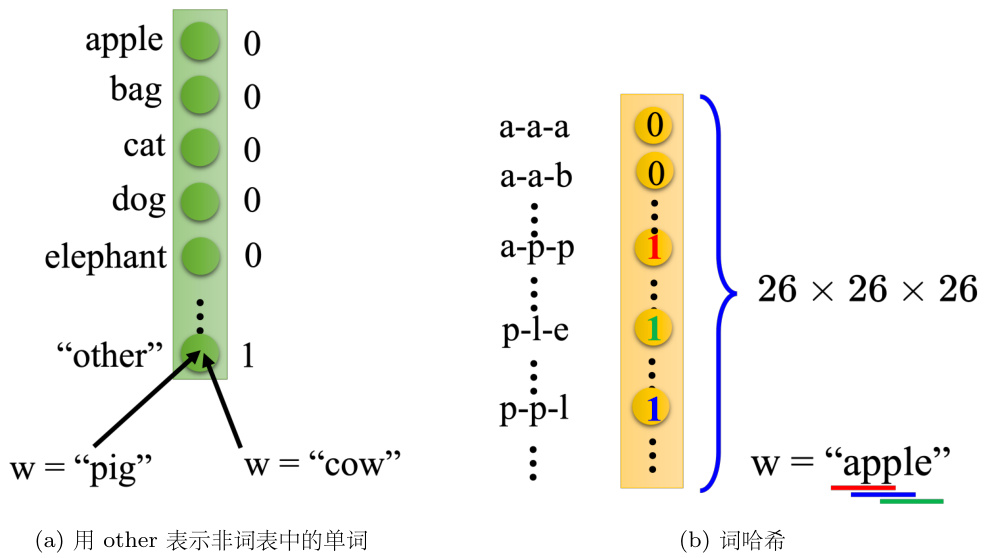
图 5.3 另一种编码方法
假设把单词表示为向量,把这个向量丢到前馈神经网络里面去,在该任务里面,输出是一个概率分布,该概率分布代表着输入单词属于每一个槽的概率,比如“上海”属于目的地的概率和“上海”属于出发地的概率,如图 5.4 所示。但是前馈网络会有问题,如图 5.5 所示,假设用户 1 说:“在 6 月 1 号抵达上海”。用户 2 说:“在 6 月 1 号离开上海”,这时候“上海”就变成了出发地。但是对于神经网络,输入一样的东西,输出就应该是一样的东西。在例子中,输入“上海”,输出要么让目的地概率最高,要么让出发地概率最高。不能一会让出发地的概率最高,一会让目的地概率最高。在这种情况下,如果神经网络有记忆力的,它记得它看过“抵达”,在看到“上海”之前;或者它记得它已经看过“离开”,在看到“上海”之前。通过记忆力,它可以根据上下文产生不同的输出。如果让神经网络是有记忆力,其就可以解决输入不同的单词,输出不同的问题。
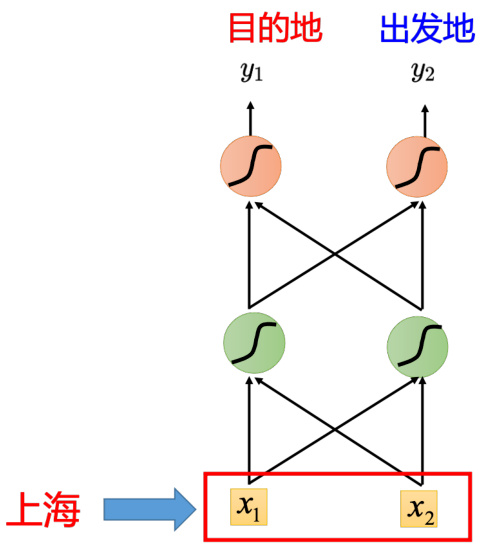
图 5.4 使用前馈神经网络预测概率分布
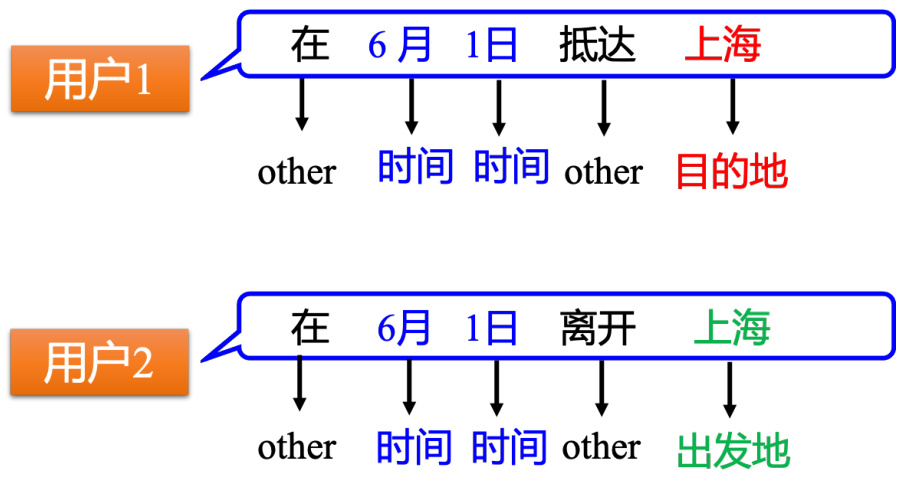
图 5.5 前馈神经网络的问题
5.2 什么是 RNN?
在 RNN 里面,每一次隐藏层的神经元产生输出的时候,该输出会被存到记忆元(memorycell),图 5.6(a)中的蓝色方块表示记忆元。下一次有输入时,这些神经元不仅会考虑输入
记忆元可简称为单元(cell),记忆元的值也可称为隐状态(hidden state)。
举个例子,假设图 5.6(b) 中的神经网络所有的权重都是 1,所有的神经元没有任何的偏置(bias)。为了便于计算,假设所有的激活函数都是线性的,输入是序列
接下来循环神经网络会将绿色神经元的输出存在记忆元里去,所以记忆元里面的值被更新为 2。如图 5.6(c) 所示,接下来再输入 [1, 1]T,接下来绿色的神经元输入为
如图 5.6(d) 所示,[6, 6]T 存到记忆元里去,接下来输入是 [2, 2]T,输出为 [16, 16]T;第二层隐藏层为 [32, 32] 。在做循环神经网络时,它会考虑序列的顺序,输入序列调换顺序之后输出不同。
因为当前时刻的隐状态使用与上一时刻隐状态相同的定义,所以隐状态的计算是循环的(recurrent),基于循环计算的隐状态神经网络被称为循环神经网络。
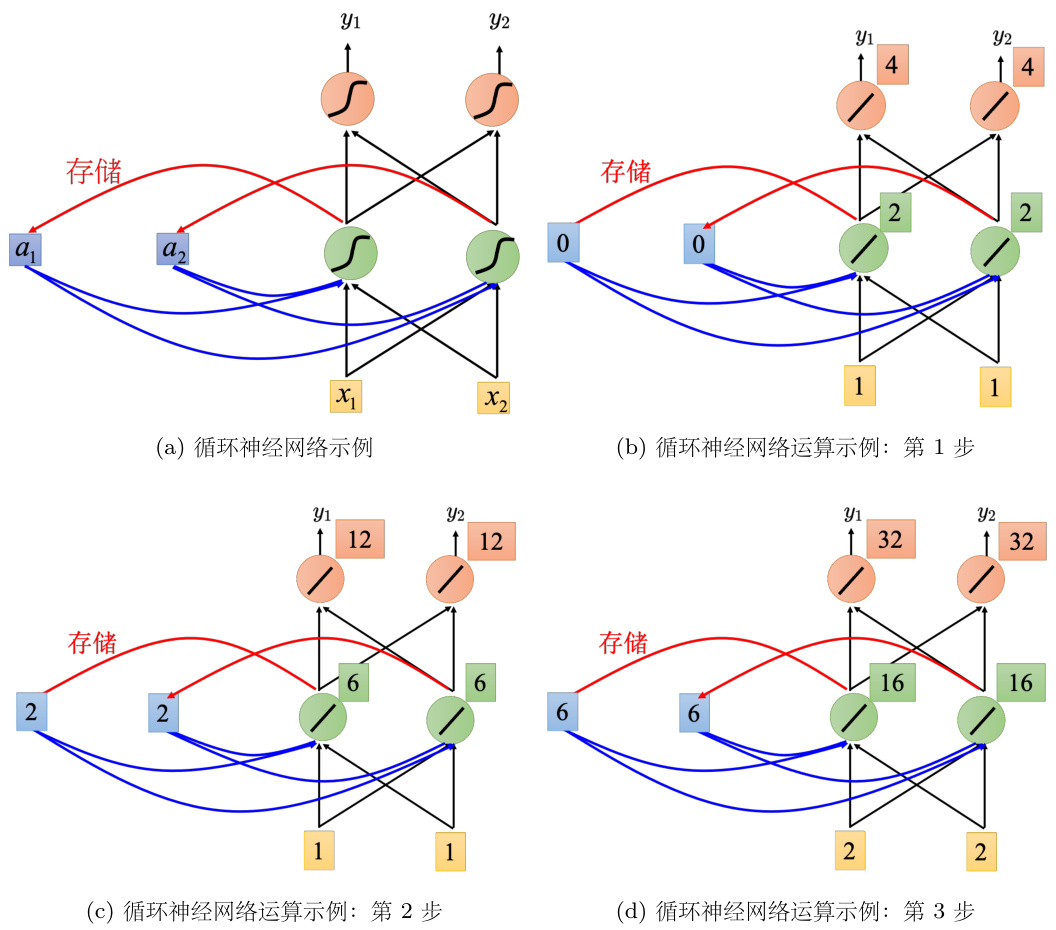
图 5.6 循环神经网络运算示例
5.3 RNN 架构
使用循环神经网络处理槽填充这件事,如图 5.7 所示。用户说:“我想在 6 月 1 日抵达上海”“抵达"就变成了一个向量“丢"到神经网络里面去,神经网络的隐藏层的输出为向量 $\mathbf{\delta}{\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta\delta}{\delta\mathbf}{\delta\mathbf}{\delta\mathbf{}\delta\mathbf{}\delta\mathbf{}\mathbf\mathbf{}\delta\mathbf{}\delta\mathbf{}\mathbf\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta\delta}\mathbf{\delta}\mathbf{\delta\delta}\mathbf{\delta}\mathbf{\delta\mathbf}{\delta\mathbf\mathbf{}\delta\mathbf\mathbf{}\mathbf\mathbf{}\delta\mathbf{}\mathbf\mathbf{\delta}\mathbf{\delta\delta}\mathbf{\delta\delta}\mathbf{\delta\mathbf}\mathbf{\mathbf\mathbf\mathbf{}\mathbf\mathbf{}\delta\mathbf\mathbf{}\mathbf\mathbf{\delta}\mathbf\mathbf{\delta\delta}\mathbf{\delta\mathbf}\mathbf{\mathbf\mathbf\mathbf{}\mathbf\mathbf\mathbf{}\mathbf\mathbf{\delta}\mathbf\mathbf{\delta\mathbf}\mathbf{\mathbf\mathbf\mathbf}{\mathbf\mathbf\mathbf{}\mathbf\mathbf\mathbf{}\mathbf\mathbf\mathbf{\mathbf\mathbf}{\mathbf\mathbf\mathbf\mathbf{}\mathbf\mathbf\mathbf{}\mathbf\mathbf\mathbf{\mathbf}\mathbf\mathbf{\mathbf\mathbf\mathbf\mathbf{}\mathbf\mathbf\mathbf{}\mathbf\mathbf\mathbf{}\mathbf\mathbf\mathbf{\mathbf\mathbf\mathbf}{\mathbf\mathbf\mathbf\mathbf{}\mathbf\mathbf\mathbf\mathbf{}\mathbf$ , $\mathbf{\delta}{\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}{\delta\mathbf}{\delta\mathbf}{\delta\mathbf}{\delta\mathbf{}\mathbf\mathbf{}\delta\mathbf{}\mathbf{\delta}\mathbf{\delta}\mathbf{}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf{\mathbf\mathbf}{\delta\mathbf}{\mathbf\mathbf{}\delta\mathbf{}\mathbf\mathbf{}\mathbf\mathbf{\delta}\mathbf{\delta}\mathbf{\delta}\mathbf\mathbf{\mathbf}{\delta\mathbf}\mathbf{\mathbf\mathbf}{\mathbf\mathbf\mathbf{}\mathbf\mathbf{}\mathbf\mathbf{\delta}\mathbf{\delta}\mathbf\mathbf{\mathbf}\mathbf{\mathbf\mathbf}{\mathbf\mathbf\mathbf{}\mathbf\mathbf{}\mathbf\mathbf\mathbf{}\mathbf\mathbf{\mathbf}\mathbf{\mathbf\mathbf}{\mathbf\mathbf\mathbf\mathbf{}\mathbf\mathbf{}\mathbf\mathbf\mathbf{}\mathbf\mathbf{\mathbf}\mathbf\mathbf{\mathbf\mathbf}{\mathbf\mathbf\mathbf}{\mathbf\mathbf\mathbf{}\mathbf\mathbf\mathbf{}\mathbf\mathbf\mathbf{}\mathbf\mathbf{\mathbf\mathbf}\mathbf{\mathbf\mathbf\mathbf}{\mathbf\mathbf\mathbf\mathbf{}\mathbf\mathbf\mathbf{}\mathbf\mathbf\mathbf{}\mathbf\mathbf\mathbf{\mathbf}\mathbf\mathbf{\mathbf\mathbf\mathbf} $ 产生“抵达”属于每一个槽填充的概率
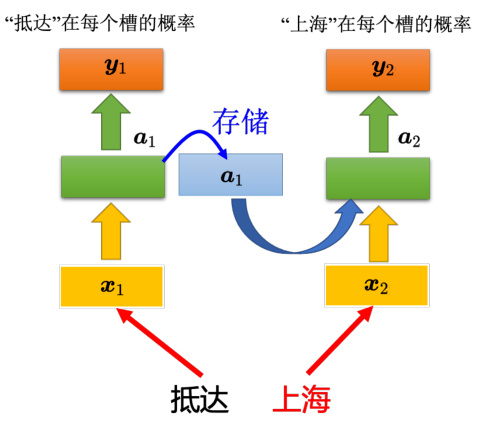
图 5.7 使用循环神经网络处理槽填充
这个不是三个网络,这是同一个网络在三个不同的时间点被使用了三次,用同样的权重用同样的颜色表示。
有了记忆元以后,输入同一个单词,希望输出不同的问题就有可能被解决。如图 5.8 所示,同样是输入“上海"这个单词,但是因为红色“上海"前接了“离开”,绿色“上海"前接了“抵达”,“离开”和“抵达”的向量不一样,隐藏层的输出会不同,所以存在记忆元里面的值会不同。虽然
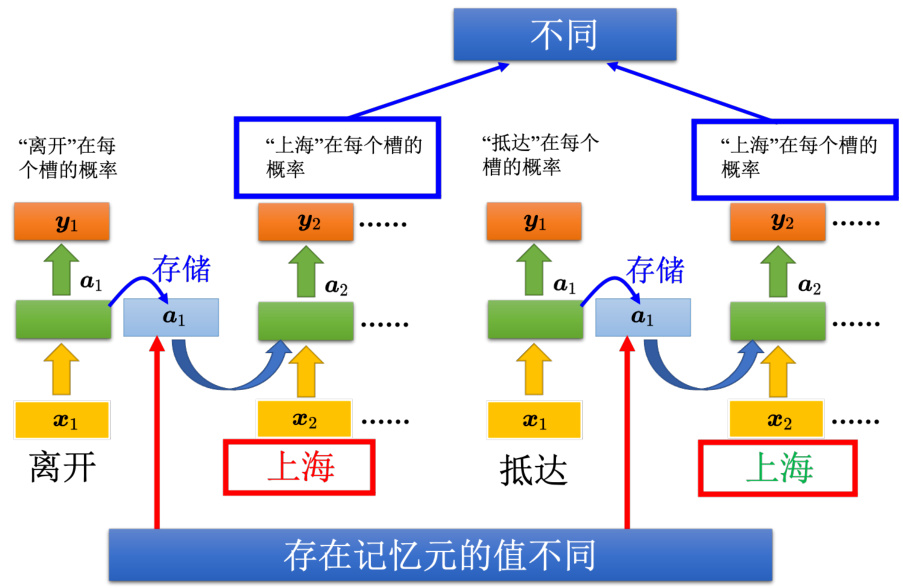
图 5.8 输入相同,输出不同示例
5.4 其他 RNN
循环神经网络的架构是可以任意设计的,之前提到的 RNN 只有一个隐藏层,但 RNN 也可以是深层的。比如把
在下一个时间点的时候,每一个隐藏层会把前一个时间点存的值再读出来,以此类推最后得到输出,这个过程会一直持续下去。
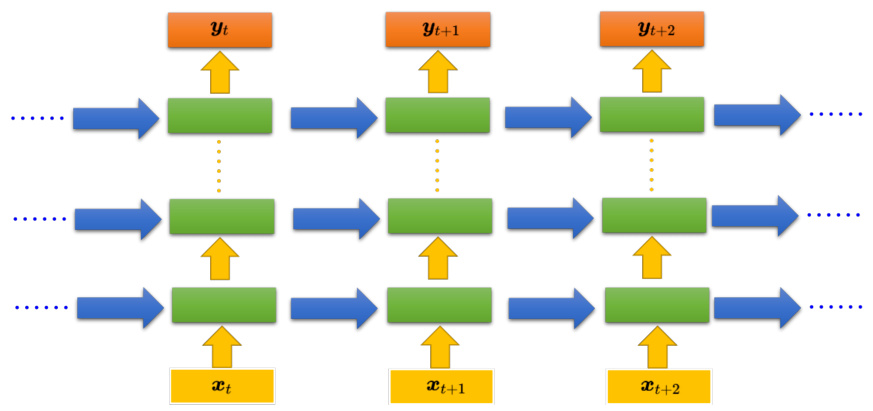
图 5.9 深层循环神经网络
5.4.1 Elman 网络 &Jordan 网络
循环神经网络会有不同的变形,如图 5.10 所示,刚才讲的是简单循环网络(Simple Re-current Network,SRN),即把隐藏层的值存起来,在下一个时间点在读出来。还有另外一种叫做 Jordan 网络,Jordan 网络存的是整个网络输出的值,它把输出值在下一个时间点在读进来,把输出存到记忆元里。Elman 网络没有目标,很难控制说它能学到什么隐藏层信息(学到什么放到记忆元里),但是 Jordan 网络是有目标,比较很清楚记忆元存储的东西。
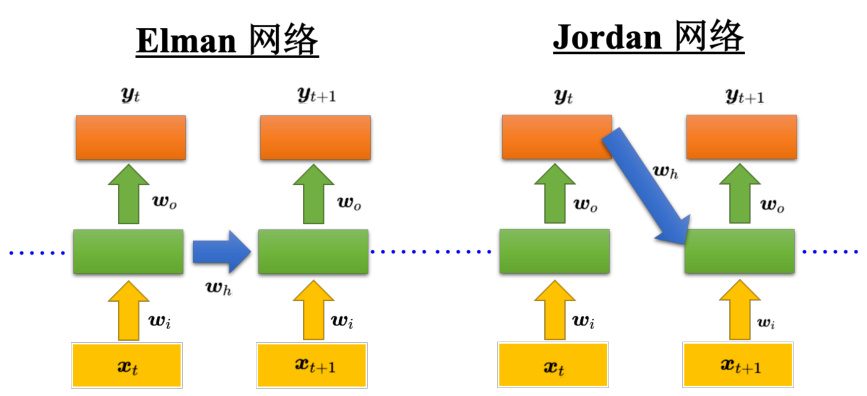
简单循环网络也称为 Elman 网络。
图 5.10 Elman 网络和 Jordan 网络
5.4.2 双向循环神经网络
循环神经网络还可以是双向。刚才 RNN 输入一个句子,它就是从句首一直读到句尾。如图 5.11 所示,假设句子里的每一个单词用
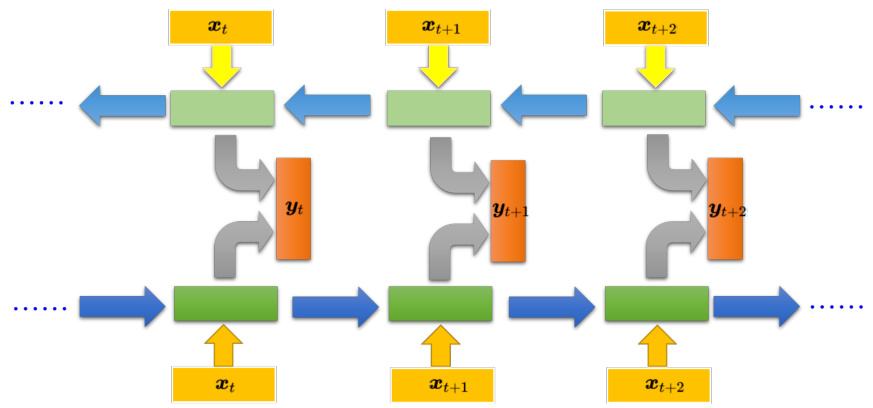
图 5.11 双向循环神经网络
5.4.3 长短期记忆网络
之前提到的记忆元是最单纯的,可以随时把值存到记忆元去,也可以把值读出来。但最常用的记忆元是长短期记忆网络(Long Short-Term Memory network,LSTM),长时间的短期记忆。LSTM 是比较复杂的。LSTM 有三个门(gate),当外界某个神经元的输出想要被写到记忆元里面的时候,必须通过一个输入门(input gate),输入门要被打开的时候,才能把值写到记忆元里面。如果把这个关起来的话,就没有办法把值写进去。至于输入门的开关是神经网络自己学的,其可以自己学什么时候要把输入门打开,什么时候要把输入门关起来。输出的地方也有一个输出门(output gate),输出门会决定外界其他的神经元能否从这个记忆元里面把值读出来。把输出门关闭的时候是没有办法把值读出来,输出门打开的时候才可以把值读出来。跟输入门一样,输出门什么时候打开什么时候关闭,网络是自己学到的。第三个门称为遗忘门(forget gate),遗忘门决定什么时候记忆元要把过去记得的东西忘掉。这个遗忘门什么时候会把存在记忆元的值忘掉,什么时候会把存在记忆元里面的值继续保留下来,这也是网络自己学到的。整个 LSTM 可以看成有 4 个输入、1 个输出。在这 4 个输入中,一个是想要被存在记忆元的值,但不一定能存进去,还有操控输入门的信号、操控输出门的信号、操控遗忘门的信号,有着四个输入但它只会得到一个输出。
“-”应该在 short-term 中间,是长时间的短期记忆。之前的循环神经网络,它的记忆元在每一个时间点都会被洗掉,只要有新的输入进来,每一个时间点都会把记忆元洗掉,所以的短期是非常短的,但如果是长时间的短期记忆元,它记得会比较久一点,只要遗忘门不要决定要忘记,它的值就会被存起来。
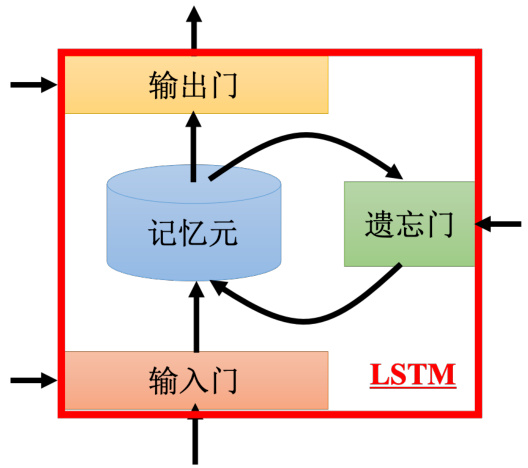
图 5.12 LSTM 结构
记忆元对应的计算公式为
如图 5.13 所示,底下这个是外界传入单元的输入,还有输入门、遗忘门和输出门。假设要被存到单元的输入叫做
接下来,把
5.4.4 LSTM 举例
如图 5.14 所示,网络里面只有一个 LSTM 的单元,输入都是三维的向量,输出都是一维的输出。这三维的向量跟输出还有记忆元的关系是这样的。假设
假设原来存到记忆元里面的值是 0,当第二个维度
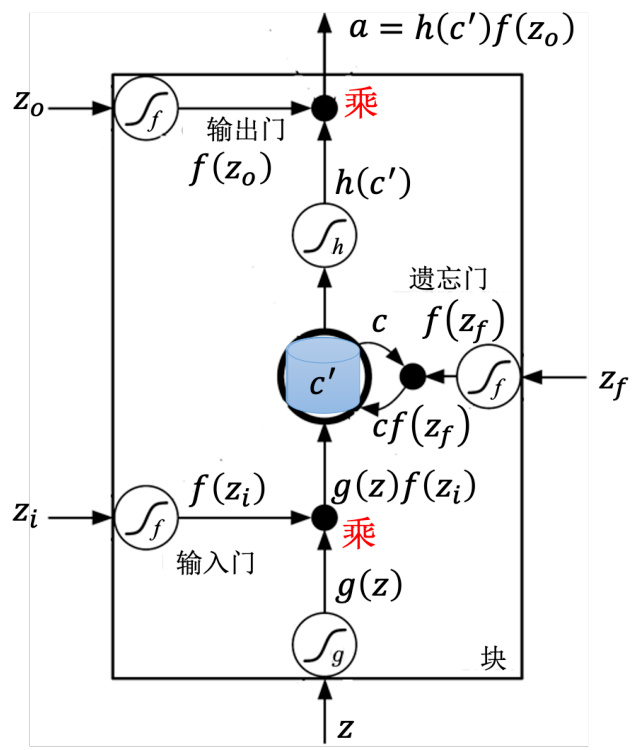
图 5.13 LSTM 记忆元示例
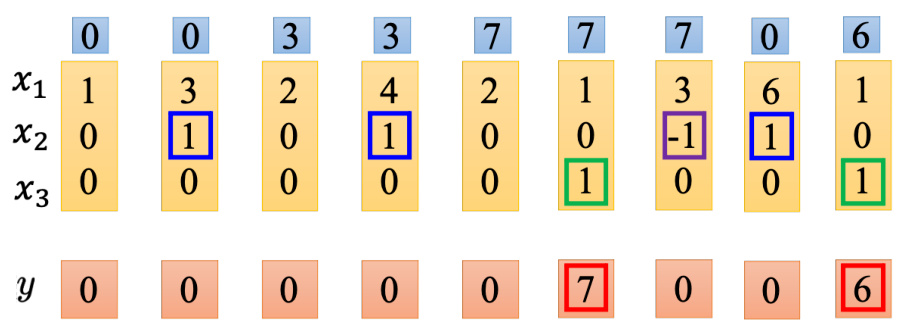
图 5.14 LSTM 示例
5.4.5 LSTM 运算示例
图 5.15 给出了 LSTM 实际的运算的例子。记忆元的四个输入标量是这样来的:输入的三维向量乘以线性变换(linear transform)后所得到的结果,
开。
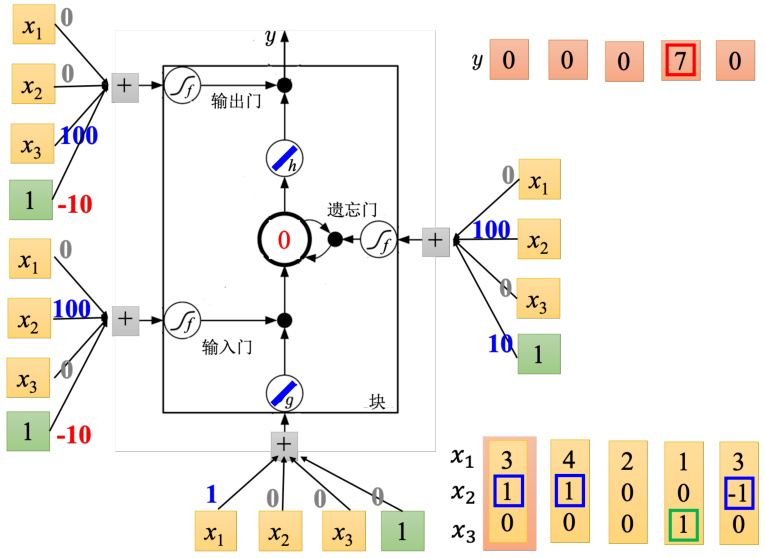
图 5.15 LSTM 运算示例
接下来,实际的输入一下看看。为了简化计算,假设
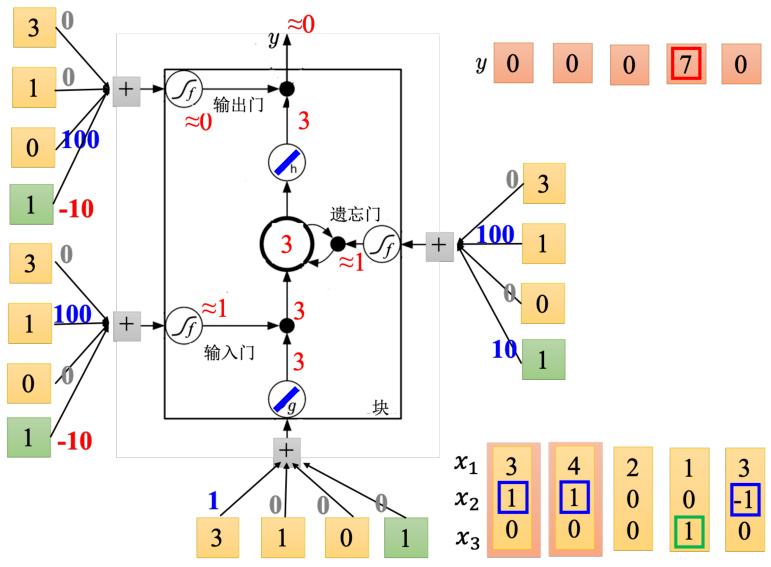
图 5.16 LSTM 运算示例:第 1 步
接下来输入
接下来输入
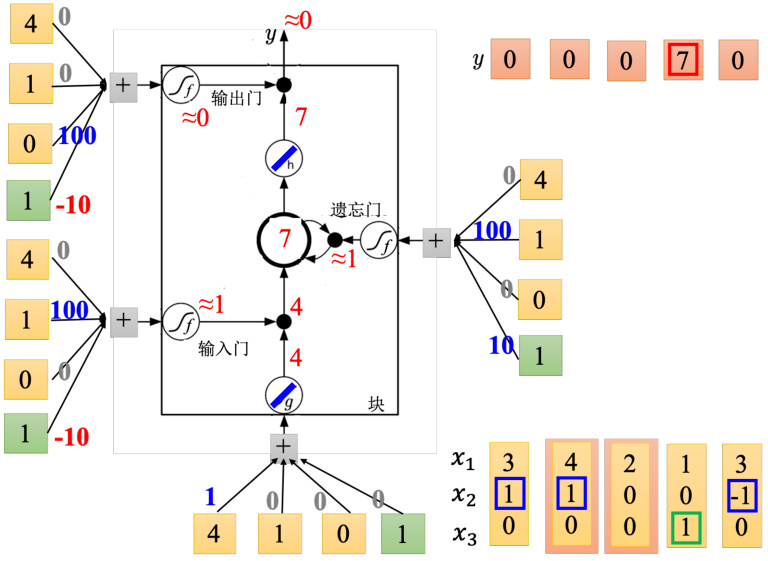
图 5.17 LSTM 运算示例:第 2 步
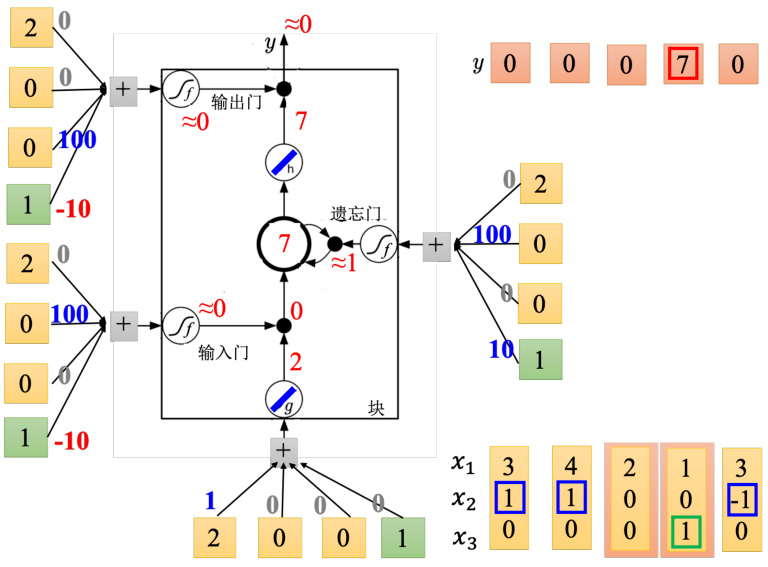
图 5.18 LSTM 运算示例:第 3 步
接下来输入
最后输入
5.5 LSTM 原理
在原来的神经网络里面会有很多的神经元,我们会把输入乘以不同的权重当做不同神经元的输入,每一个神经元都是一个函数,输入一个值然后输出一个值。但是如果是 LSTM 的话,只要把 LSTM 想成是一个神经元。所以要用一个 LSTM 的神经元,其实就是原来简单的神经元换成 LSTM。
如图 5.22 所示,为了简化,假设隐藏层只有两个神经元,输入
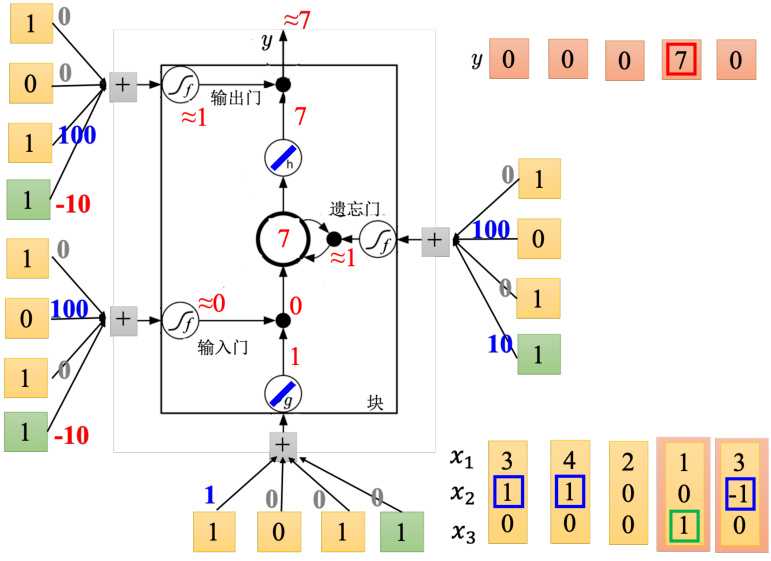
图 5.19 LSTM 运算示例:第 4 步
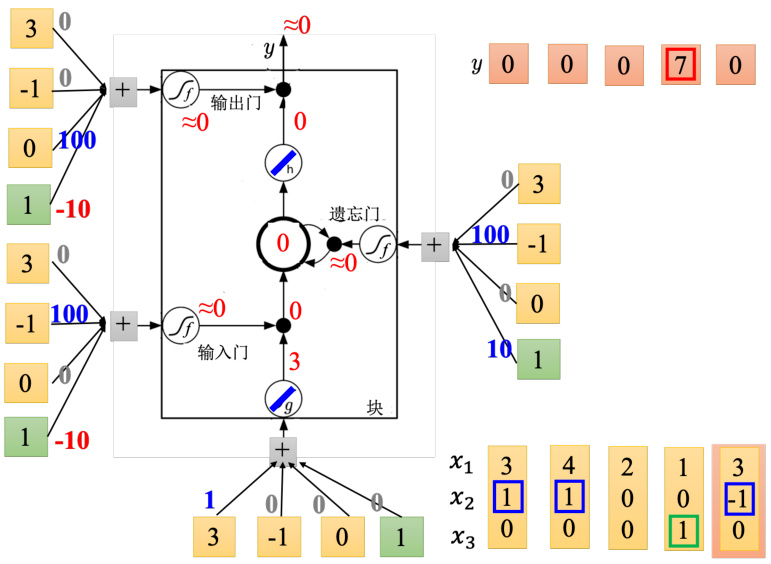
图 5.20 LSTM 运算示例:第 5 步
如图 5.23 所示,假设有一整排的 LSTM,这些 LSTM 里面的记忆元都存了一个值,把所有的值接起来就变成了向量,写为
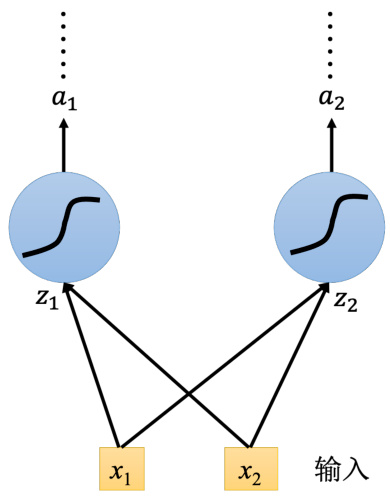
图 5.21 把 LSTM 想成一个神经元
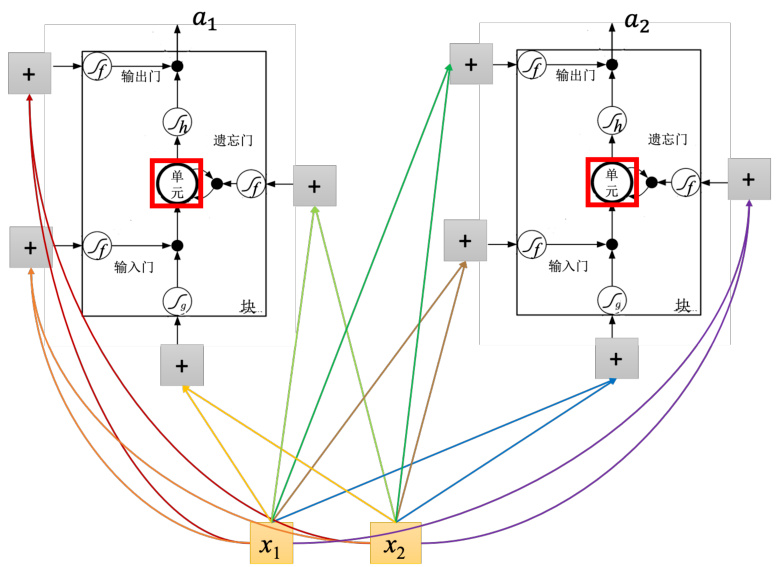
图 5.22 LSTM 需要 4 个输入
如图 5.24 所示,输入分别就是
之前那个相加以后的结果就是记忆元里面存放的值
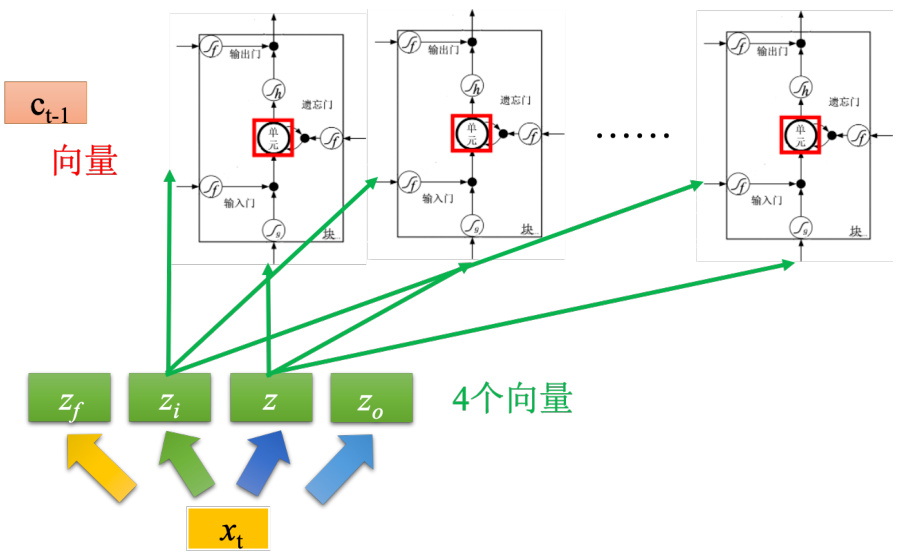
图 5.23 输入向量与记忆元的关系
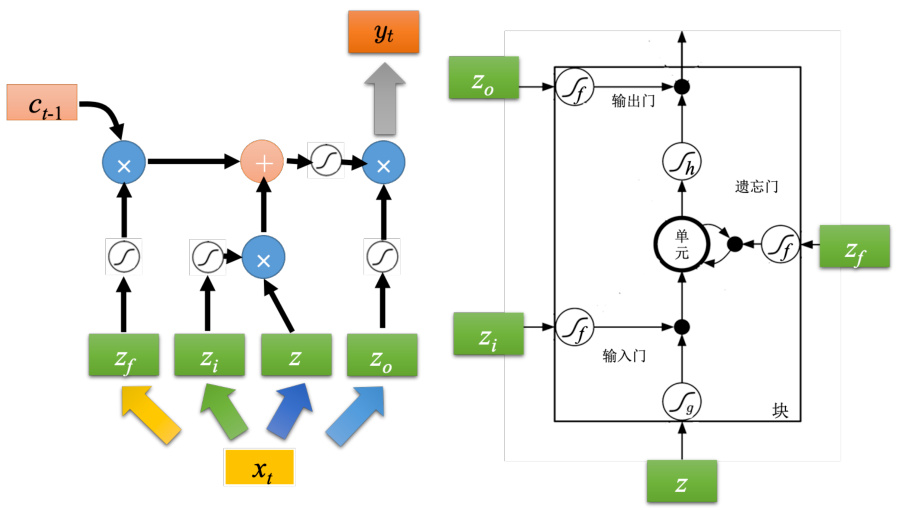
图 5.24 记忆元一起运算示例
LSTM 通常不会只有一层,若有五六层的话,如图 5.26 所示。一般做 RNN 的时候,其实指的就用 LSTM。
门控循环单元(Gated Recurrent Unit,GRU)是 LSTM 稍微简化的版本,它只有两个门。虽然少了一个门,但其性能跟 LSTM 差不多,少了 1/3 的参数,也是比较不容易过拟合。
5.6 RNN 学习方式
如果要做学习,需要定义一个损失函数(loss function)来评估模型的好坏,选一个参数要让损失最小。以槽填充为例,如图 5.27 所示,给定一些句子,要给句子一些标签,告诉机器说第一个单词它是属于 other 槽,“上海”是目的地槽,“on”属于 other 槽,“June”和“1st”属于时间槽。“抵达”丢到循环神经网络的时候,循环神经网络会得到一个输出
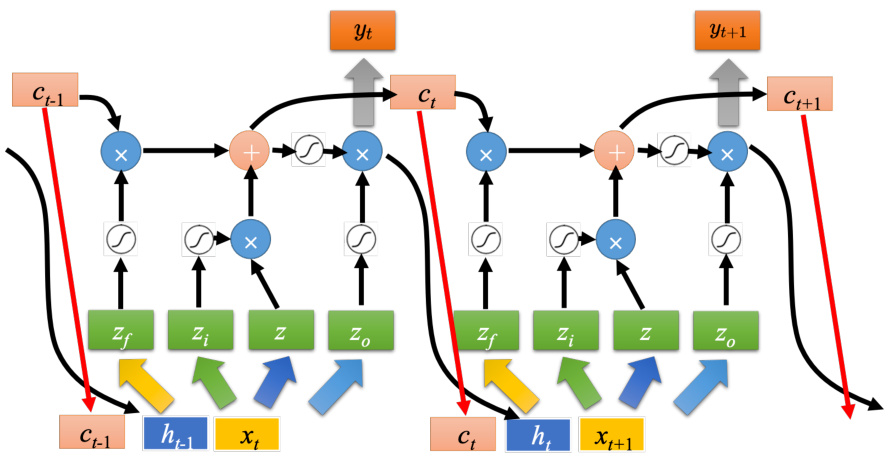
图 5.25 peephole 连接
有了这个损失函数以后,对于训练也是用梯度下降来做。也就是现在定义出了损失函数
RNN 的训练是比较困难的,如图 5.29 所示。一般而言,在做训练的时候,期待学习曲线是像蓝色这条线,这边的纵轴是总损失(total loss),横轴是回合的数量,我们会希望随着回合的数量越来越多,随着参数不断的更新,损失会慢慢地下降,最后趋向收敛。但是不幸的是,在训练循环神经网络的时候,有时候会看到绿色这条线。如果第一次训练循环神经网络,绿色学习曲线非常剧烈的抖动,然后抖到某个地方,我们会觉得这程序有 bug。
如图 5.30 所示,RNN 的误差表面是总损失的变化是非常陡峭的或崎岖的。误差表面有一些地方非常平坦,一些地方非常陡峭。纵轴是总损失,x 和 y 轴代表是两个参数。这样会造成什么样的问题呢?假设我们从橙色的点当做初始点,用梯度下降开始调整参数,更新参数,可能会跳过一个悬崖,这时候损失会突然爆长,损失会非常上下剧烈的震荡。有时候我们可能会遇到更惨的状况,就是以正好我们一脚踩到这个悬崖上,会发生这样的事情,因为在悬崖上的梯度很大,之前的梯度会很小,所以措手不及,因为之前梯度很小,所以可能把学习率调的比较大。很大的梯度乘上很大的学习率结果参数就更新很多,整个参数就飞出去了。裁剪(clipping)可以解决该问题,当梯度大于某一个阈值的时候,不要让它超过那个阈值,当梯度大于 15 时,让梯度等于 15 结束。因为梯度不会太大,所以我们要做裁剪的时候,就算是踩着这个悬崖上,也不飞出来,会飞到一个比较近的地方,这样还可以继续做 RNN 的训练。
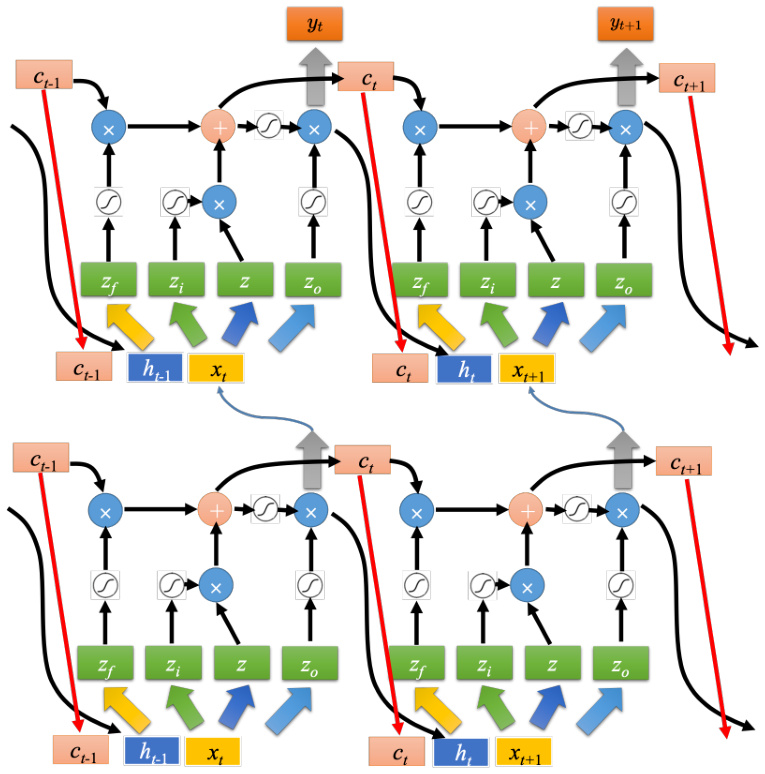
图 5.26 多层 LSTM
之前讲过 ReLU 激活函数的时候,梯度消失(vanishing gradient)来源于 Sigmoid 函数。但 RNN 会有很平滑的误差表面不是来自于梯度消失。把 Sigmoid 函数换成 ReLU,其实在 RNN 性能通常是比较差的,所以激活函数并不是关键点。
有更直观的方法来知道一个梯度的大小,可以把某一个参数做小小的变化,看它对网络输出的变化有多大,就可以测出这个参数的梯度大小,如图 5.31 所示。举一个很简单的例子,只有一个神经元,这个神经元是线性的。输入没有偏置,输入的权重是 1,输出的权重也是 1,转移的权重是
如图 5.32 所示,假设给神经网络的输入是
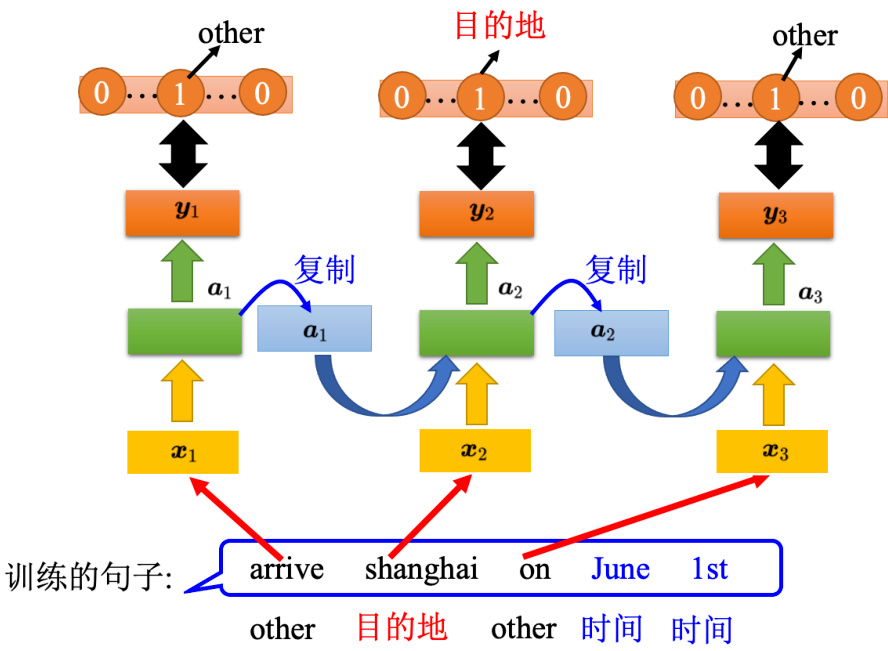
图 5.27 RNN 计算损失示意
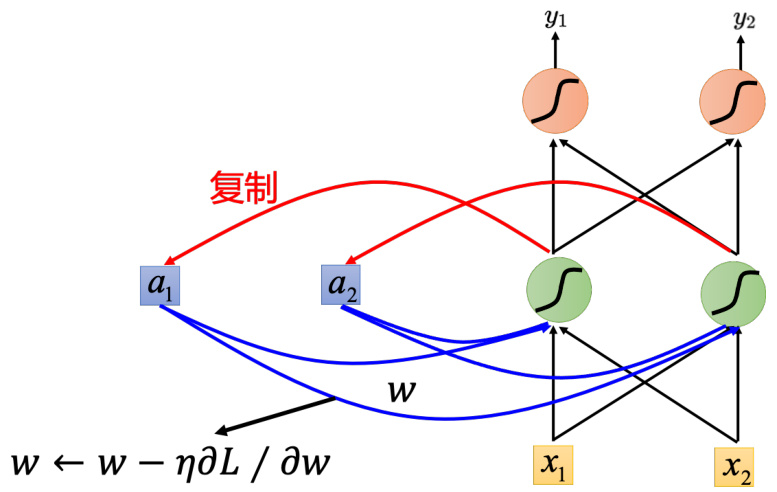
图 5.28 随时间反向传播
5.7 如何解决 RNN 梯度消失或者爆炸
有什么样的技巧可以解决这个问题呢?广泛被使用的技巧是 LSTM,LSTM 可以让误差表面不要那么崎岖。它会把那些平坦的地方拿掉,解决梯度消失的问题,不会解决梯度爆炸(gradient exploding)的问题。有些地方还是非常的崎岖的,有些地方仍然是变化非常剧烈的,但是不会有特别平坦的地方。如果做 LSTM 时,大部分地方变化的很剧烈,所以做 LSTM的时候,可以把学习率设置的小一点,保证在学习率很小的情况下进行训练。
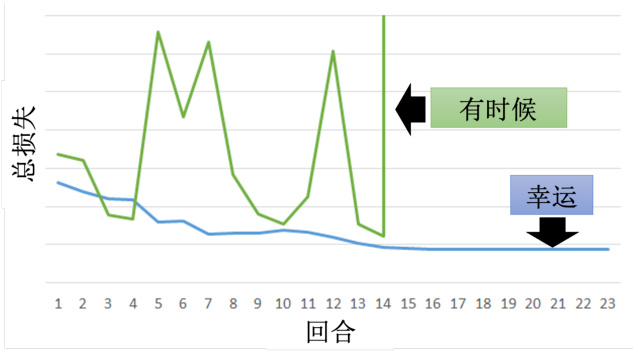
图 5.29 训练 RNN 时的学习曲线
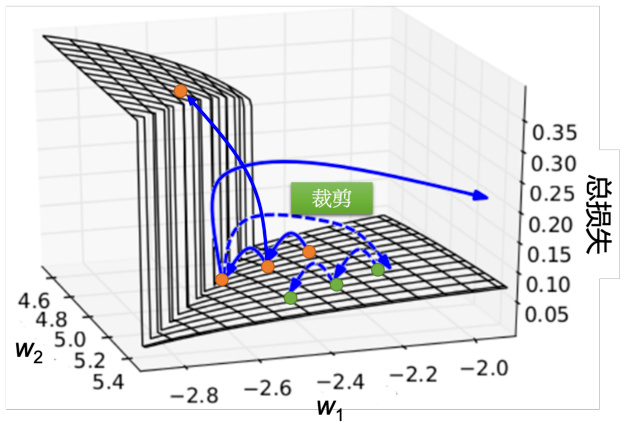
图 5.30 RNN 训练中的裁剪技巧
Q: 为什么 LSTM 可以解决梯度消失的问题,可以避免梯度特别小呢?为什么把 RNN换成 LSTM?。
A:LSTM 可以处理梯度消失的问题。用这边的式子回答看看。RNN 跟 LSTM 在面对记忆元的时候,它处理的操作其实是不一样的。在 RNN 里面,在每一个时间点,神经元的输出都要记忆元里面去,记忆元里面的值都是会被覆盖掉。但是在 LSTM 里面不样,它是把原来记忆元里面的值乘上一个值再把输入的值加起来放到单元里面。所以它的记忆和输入是相加的。LSTM 和 RNN 不同的是,如果权重可以影响到记忆元里面的值,一旦发生影响会永远都存在。而 RNN 在每个时间点的值都会被格式化掉,所以只要这个影响被格式化掉它就消失了。但是在 LSTM 里面,一旦对记忆元造成影响,影响一直会被留着,除非遗忘门要把记忆元的值洗掉。不然记忆元一旦有改变,只会把新的东西加进来,不会把原来的值洗掉,所以它不会有梯度消失的问题。
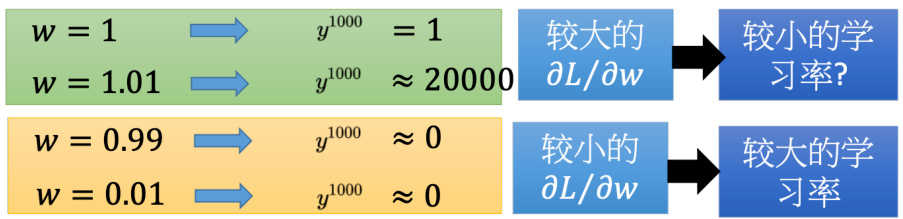
图 5.31 参数变化对网络输出的影响
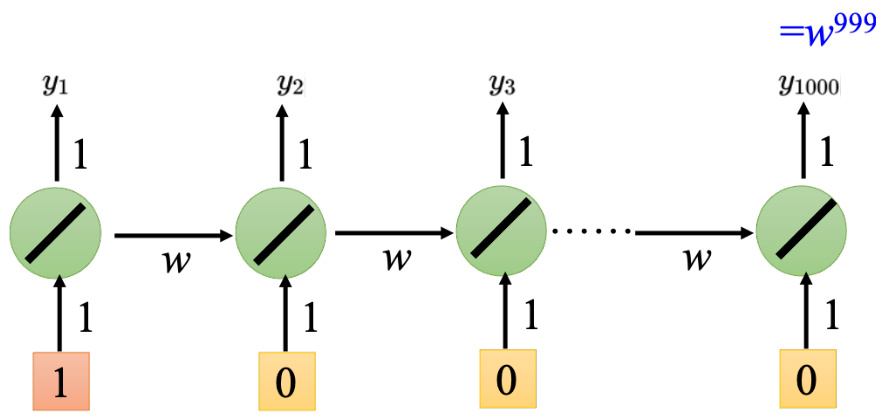
图 5.32 RNN 难以训练的原因
遗忘门可能会把记忆元的值洗掉。其实 LSTM 的第一个版本就是为了解决梯度消失的问题,所以它是没有遗忘门,遗忘门是后来才加上去的。甚至有个传言是:在训练 LSTM 的时候,要给遗忘门特别大的偏置,确保遗忘门在多数的情况下都是开启的,只要少数的情况是关闭的。
有另外一个版本用门操控记忆元,叫做 GRU,LSTM 有三个门,而 GRU 有两个门,所以 GRU 需要的参数是比较少的。因为它需要的参数量比较少,所以它在训练的时候是比较鲁棒的。如果训练 LSTM 的时候,过拟合的情况很严重,可以试下 GRU。GRU 的精神就是:旧的不去,新的不来。它会把输入门跟遗忘门联动起来,也就是说当输入门打开的时候,遗忘门会自动的关闭 (格式化存在记忆元里面的值),当遗忘门没有要格式化里面的值,输入门就会被关起来。也就是要把记忆元里面的值清掉,才能把新的值放进来。
其实还有其他技术可以处理梯度消失的问题。比如顺时针循环神经网络(clockwise RNN)[1] 或结构约束的循环网络(Structurally Constrained Recurrent Network,SCRN)[2] 等等。
论文“A Simple Way to Initialize Recurrent Networks of Rectified Linear Units”[3] 采用了不同的做法。一般的 RNN 用单位矩阵(identity matrix)来初始化转移权重和 ReLU 激活函数可以得到很好的性能。刚才不是说用 ReLU 的性能会比较差,如果用一般训练的方法随机初始化权重,ReLU 跟 sigmoid 函数来比的话,sigmoid 性能会比较好。但是使用了单位矩阵,这时候用 ReLU 性能会比较好。
5.8 RNN 其他应用
槽填充的例子中假设输入跟输出的数量是一样的,也就是说输入有几个单词,我们就给每一个单词槽标签,RNN 可以做到更复杂的事情。
5.8.1 多对一序列
比如输入是一个序列,输出是一个向量。情感分析(sentiment analysis)是典型的应用,如图 5.33 所示,某家公司想要知道,他们的产品在网上的评价是正面的还是负面的。他们可能会写一个爬虫,把跟他们产品有关的文章都爬下来。那这一篇一篇的看太累了,所以可以用一个机器学习的方法学习一个分类器(classifier)来判断文档的正、负面。或者在电影上,情感分析就是给机器看很多的文章,机器要自动判断哪些文章是正类,哪些文章是负类。
机器可以学习一个循环神经网络,输入是字符序列,循环神经网络把这个序列读过一遍。在最后一个时间点,把隐藏层拿出来,在通过几个变换,就可以得到最后的情感分析。
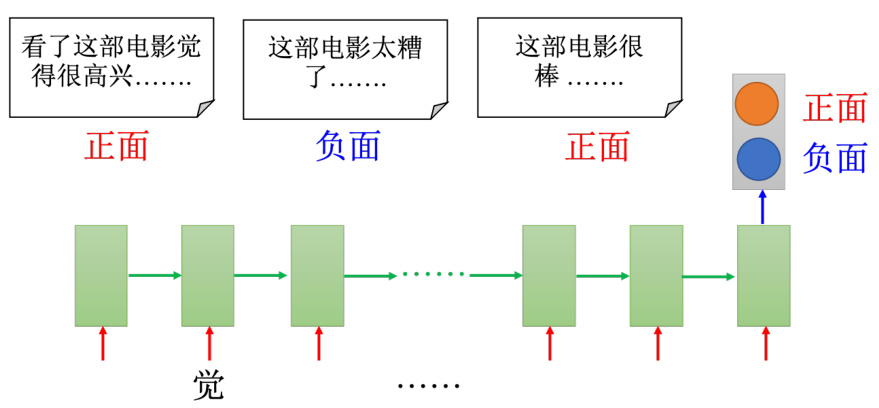
情感分析是一个分类问题,但是因为输入是序列,所以用 RNN 来处理。
用 RNN来作关键术语抽取(key term extraction)。关键术语抽取意思就是说给机器看一个文章,机器要预测出这篇文章有哪些关键单词。如图 5.34 所示,如果能够收集到一些训练数据 (一些文档,这些文档都有标签,哪些单词是对应的,那就可以直接训练一个 RNN),那这个RNN 把文档当做输入,通过嵌入层(embedding layer),用 RNN 把这个文档读过一次,把出现在最后一个时间点的输出拿过来做注意力,可以把这样的信息抽出来再丢到前馈神经网络得到最后的输出。

图 5.33 情感分析示例
图 5.34 关键术语抽取
5.8.2 多对多序列
RNN 也可以处理多对多的问题,比如输入和输出都是序列,但输出序列比输入序列短。如图 5.35 所示,在语音识别这个任务里面输入是声音序列,一句话就是一段声音信号。一般处理声音信号的方式就是在这个声音信号里面,每隔一小段时间,就把它用向量来表示。这个一小段时间是很短的(比如 0.01 秒)。那输出序列是字符序列。
如果是原来的 RNN(槽填充的那个 RNN),把这一串输入丢进去,它充其量只能做到,告诉我们每一个向量对应到哪一个字符。加入说中文的语音识别的话,那输出目标理论上就是这个世界上所有可能中文的单词,常用的可能是八千个,RNN 分类器的数量可能就是八千个。虽然很大,但也是没有办法做的。但是充其量只能做到说:每一个向量属于一个字符。每一个输入对应的时间间隔是很小的(0.01 秒),所以通常是好多个向量对应到同一个字符。所以识别结果为“好好好棒棒棒棒棒”这不是语音识别的结果。有一招叫做修剪(trimming),即把重复的东西拿掉,就变成“好棒”。这样会有一个严重的问题,因为它没有识别“好棒棒”。
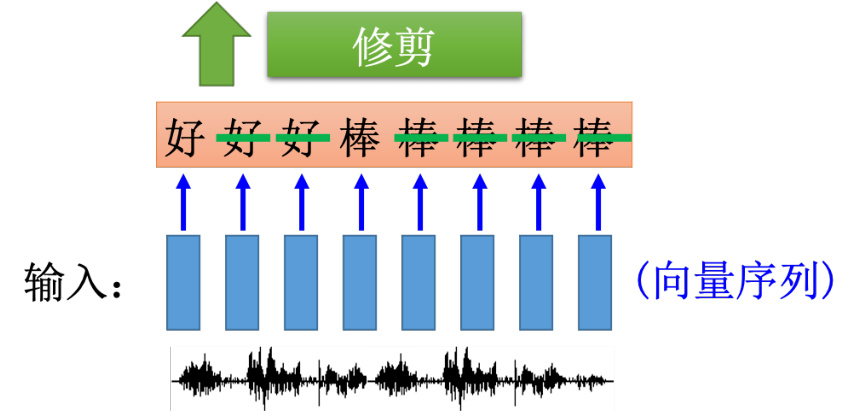
输出:“好棒”(字符序列)
需要把“好棒”跟“好棒棒”分开来,怎么办,有一招叫做“CTC”,如图 5.36 所示,在输出时候,不只是输出所有中文的字符,还可以输出一个符号”null”,其代表没有任何东西。所以输入一段声音特征序列,它的输出是“好 null null 棒 null null null null”,然后把“null”的部分拿掉,它就变成“好棒”。如果我们输入另外一个序列,它的输出是“好 null null 棒 null 棒 nullnull”,然后把“null”拿掉,所以它的输出就是“好棒棒”。这样就可以解决叠字的问题了。
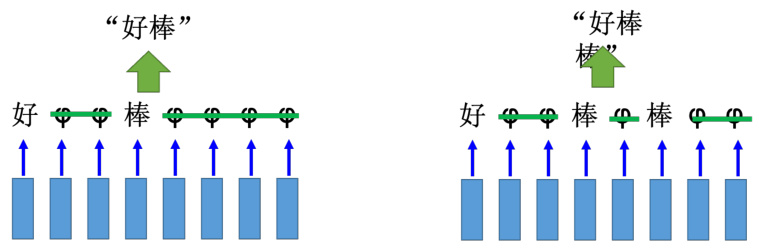
图 5.35 语音识别示例
图 5.36 CTC 技巧
CTC 怎么做训练呢?如图 5.37 所示,CTC 在做训练的时候,手上的训练数据就会告诉我们说,这一串声音特征对应到这一串字符序列,但它不会告诉我们说“好”是对应第几个字符到第几个字符。这时候要穷举所有可能的对齐,简单来说,我们不知道“好”对应到那几个字符,“棒”对应到哪几个字符。假设我们所有的状况都是可能的。可能第一个是“好 null 棒 nullnull null”,可能是“好 null null 棒 null null”,也可能是“好 null null null 棒 null”。假设全部都是对的,一起训练。穷举所有的可能,可能性太多了。
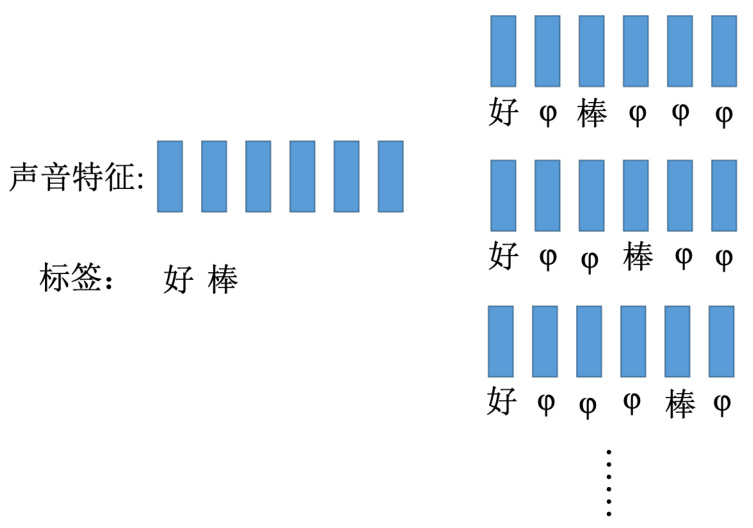
图 5.37 CTC 训练
在做英文识别的时候,RNN 输出目标就是字符(英文的字母
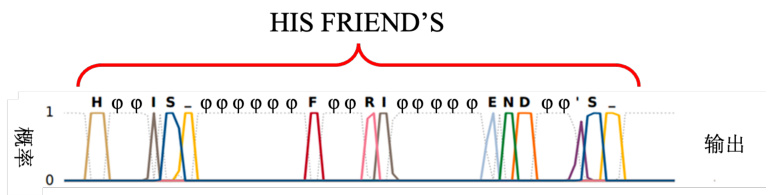
图 5.38 CTC 语音识别示例
5.8.3 序列到序列
另一个 RNN 的应用是序列到序列(Sequence-to-Sequence,Seq2Seq)学习,在序列到序列学习里面,RNN 的输入跟输出都是序列 (但是两者的长度是不一样的)。刚在在 CTC时,输入比较长,输出比较短。在这边我们要考虑的是不确定输入跟输出谁比较长谁比较短。比如机器翻译(machine translation),输入英文单词序列把它翻译成中文的字符序列。英文和中文序列的长短是未知的。
假如输入机器学习,然后用 RNN 读过去,然后在最后一个时间点,这个记忆元里面就存了所有输入序列的信息,如图 5.39 所示。
接下来,我们让机器吐一个字符(“机”),就让它输出下一个字符,把之前的输出出来的字符当做输入,再把记忆元里面的值读进来,它就会输出“器”。那这个“机”怎么接到这个地方呢,有很多支支节节的技巧。在下一个时间输入“器”,输出“学”,然后输出“习”,然后一直输出下去,如图 5.40 所示。
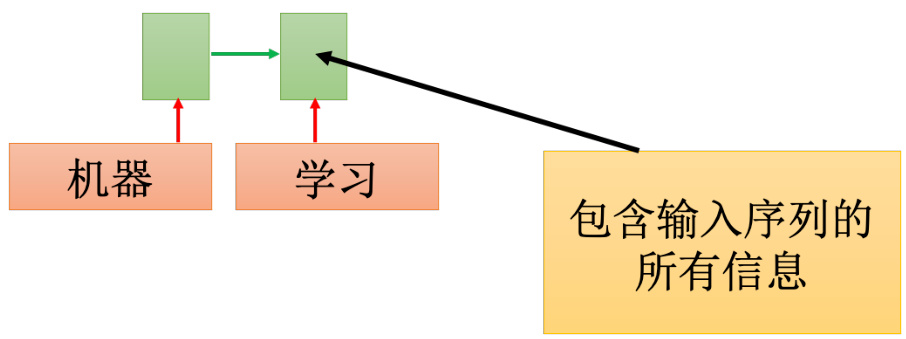
图 5.39 记忆元存储所有序列信息
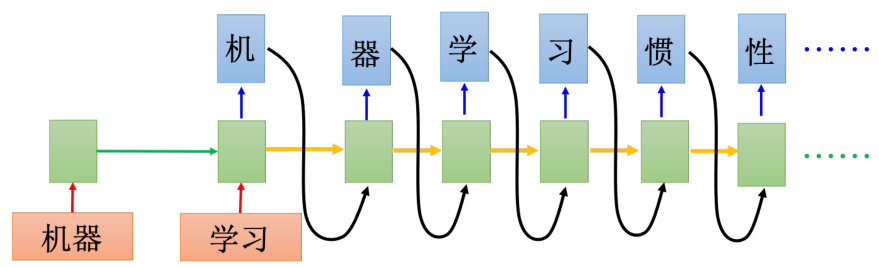
图 5.40 RNN 会一直生成字符
要怎么阻止让它产生单词呢?要多加一个符号“断”,所以机器的输出不是只有字符,它还有一个可能输出“断”。如果“习”后面是符号
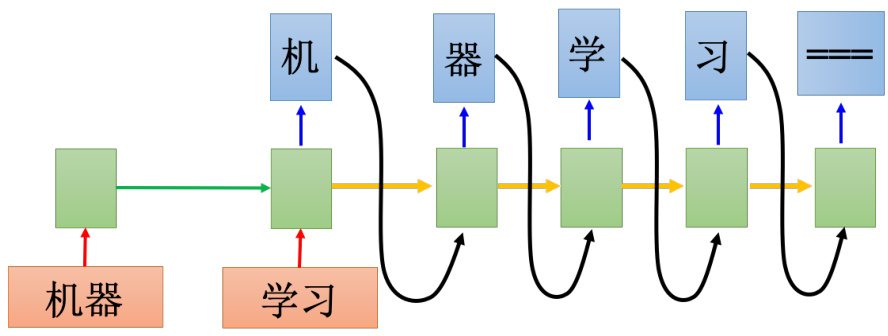
图 5.41 添加截止符号
序列到序列的技术也被用到句法解析(syntactic parsing)。句法解析,让机器看一个句子,得到句子结构树。如图 5.42 所示,只要把树状图描述成一个序列,比如:“John has a dog.”,序列到序列学习直接学习一个序列到序列模型,其输出直接就是句法解析树,这个是可以训练的起来的。LSTM 的输出的序列也是符合文法结构,左、右括号都有。
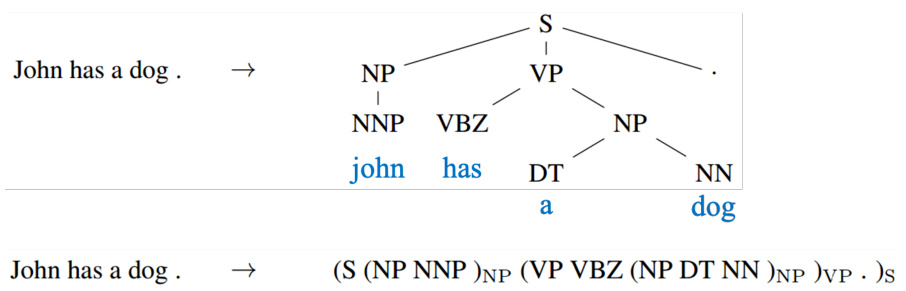
图 5.42 句法解析示例
要将一个文档表示成一个向量,如图 5.43 所示,往往会用词袋(Bag-of-Words,BoW)的方法,用这个方法的时候,往往会忽略掉单词顺序信息。举例来说,有一个单词序列是“whiteblood cells destroying an infection",另外一个单词序列是:“an infection destroying white bloodcells”,这两句话的意思完全是相反的。但是我们用词袋的方法来描述的话,他们的词袋完全是一样的。它们里面有完全一摸一样的六个单词,因为单词的顺序是不一样的,所以他们的意思一个变成正面的,一个变成负面的,他们的意思是很不一样的。
可以用序列到序列自编码器这种做法来考虑单词序列顺序的情况下,把一个文档变成一个向量。

图 5.43 文档转成向量示例
参考文献
[1] KOUTNIK J, GREFF K, GOMEZ F, et al. A clockwork rnn[C]//International conference on machine learning. PMLR, 2014: 1863-1871.
[2] MIKOLOV T, JOULIN A, CHOPRA S, et al. Learning longer memory in recurrent neural networks[C]//ICLR. 2015.
[3] LE Q V, JAITLY N, HINTON G E. A simple way to initialize recurrent networks of rectified linear units[J]. arXiv preprint arXiv:1504.00941, 2015.