第 7 章 Transformer
Transformer 是一个基于自注意力的序列到序列模型,与基于循环神经网络的序列到序列模型不同,其可以能够并行计算。本章从两方面介绍了 Transformer,一方面介绍了 Trans-former 的结构,即编码器和解码器、编码器-解码器注意力,另一方面介绍了 Transformer 的训练过程以及 序列到序列 模型的训练技巧。
7.1 序列到序列模型
序列到序列模型输入和输出都是一个序列,输入与输出序列长度之间的关系有两种情况。第一种情况下,输入跟输出的长度一样;第二种情况下,机器决定输出的长度。序列到序列模型有广泛的应用,通过这些应用可以更好地了解序列到序列模型。
7.1.1 语音识别、机器翻译与语音翻译
序列到序列模型的常见应用如图 7.1 所示。
• 语音识别:输入是声音信号,输出是语音识别的结果,即输入的这段声音信号所对应的文字。我们用圆圈来代表文字,比如每个圆圈代表中文里面的一个方块字。输入跟输出的长度有一些关系,但没有绝对的关系,输入的声音信号的长度是
• 机器翻译:机器输入一个语言的句子,输出另外一个语言的句子。输入句子的长度是
• 语音翻译:我们对机器说一句话,比如“machine learning”,机器直接把听到的英语的声音信号翻译成中文。
Q: 既然把语音识别系统跟机器翻译系统接起来就能达到语音翻译的效果,那么为什么要做语音翻译?
A: 世界上很多语言是没有文字的,无法做语音识别。因此需要对这些语言做语音翻译,直接把它翻译成文字。
以闽南语的语音识别为例,闽南语的文字不是很普及,一般人不一定能看懂。因此我们想做语音的翻译,对机器讲一句闽南语,它直接输出的是同样意思的白话文的句子,这样一般人就可以看懂。我们可以训练一个神经网络,该神经网络输入某一种语言的声音信号,输出是另外一种语言的文字,需要学到闽南语的声音信号跟白话文文字的对应关系。YouTube 上面有很多的乡土剧,乡土剧是闽南语语音、白话文字幕,所以只要下载它的闽南语语音和白话文字幕,这样就有闽南语声音信号跟白话文之间的对应关系,就可以训练一个模型来做闽南语的语音识别:输入闽南语,输出白话文。李宏毅实验室下载了 1500 个小时的乡土剧的数据,并用其来训练一个语音识别系统。这会有一些问题,比如乡土剧有很多噪声、音乐,乡土剧的字幕不一定跟声音能对应起来。可以忽略这些问题,直接训练一个模型,输入是声音信号,输出直接是白话文的文字,这样训练能够做一个闽南语语音识别系统。
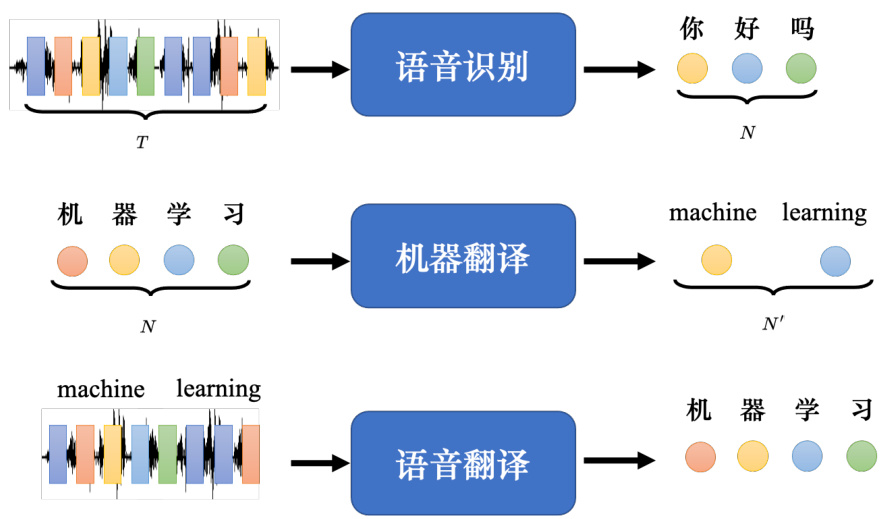
图 7.1 序列到序列的常见应用
7.1.2 语音合成
输入文字、输出声音信号就是语音合成(Text-To-Speech,TTS)。现在还没有真的做端到端(end-to-end)的模型,以闽南语的语音合成为例,其使用的模型还是分成两阶,首先模型会先把白话文的文字转成闽南语的拼音,再把闽南语的拼音转成声音信号。从闽南语的拼音转成声音信号这一段是通过序列到序列模型 echotron 实现的。
7.1.3 聊天机器人
除了语音以外,文本也很广泛的使用了序列到序列模型。比如用序列到序列模型可用来训练一个聊天机器人。聊天机器人就是我们对它说一句话,它要给出一个回应。因为聊天机器人的输入输出都是文字,文字是一个向量序列,所以可用序列到序列的模型来做一个聊天机器人。我们可以收集大量人的对话(比如电视剧、电影的台词等等),如图 7.2 所示,假设在对话里面有出现,一个人说:“Hi”,另外一个人说:“Hello! How are you today?”。我们可以教机器,看到输入是“Hi”,输出就要跟“Hello! How are you today?”越接近越好。

图 7.2 聊天机器人的例子
7.1.4 问答任务
序列到序列模型在自然语言处理的领域的应用很广泛,而很多自然语言处理的任务都可以想成是问答(Question Answering,QA)的任务,比如下面是一些例子。
• 翻译。机器读的文章是一个英语句子,问题是这个句子的德文翻译是什么?输出的答案就是德文。
• 自动做摘要:给机器读一篇长的文章,让它把长的文章的重点找出来,即给机器一段文字,问题是这段文字的摘要是什么。
• 情感分析:机器要自动判断一个句子是正面的还是负面的。如果把情感分析看成是问答的问题,问题是给定句子是正面还是负面的,希望机器给出答案。
问答就是给机器读一段文字,问机器一个问题,希望它可以给出一个正确的答案。
因此各式各样的自然语言处理的问题往往都可以看作是问答的问题,而问答的问题可以用序列到序列模型来解。序列到序列模型的输入是一篇文章和一个问题,输出就是问题的答案。问题加文章合起来是一段很长的文字,答案是一段文字。只要是输入一个序列,输出是一个序列,序列到序列模型就可以解。虽然各种自然语言处理的问题都能用序列到序列模型来解,但是对多数自然语言处理的任务或对多数的语音相关的任务而言,往往为这些任务定制化模型会得到更好的结果。序列到序列模型就像瑞士刀,瑞士刀可以解决各式各样的问题,砍柴可以用瑞士刀,切菜也可以用瑞士刀,但是它不一定是最好用的。因此针对各种不同的任务定制的模型往往比只用序列到序列模型的模型更好。谷歌 Pixel 4 手机用于语音识别的模型不是序列到序列模型,而是 RNN-Transducer 模型,这种模型是为了语音的某些特性所设计的,表现更好。
7.1.5 句法分析
很多问题都可以用序列到序列模型来解,以句法分析(syntactic parsing)为例,如图 7.3所示,给机器一段文字:比如“deep learning is very powerful”,机器要产生一个句法的分析树,即句法树(syntactic tree)。通过句法树告诉我们 deep 加 learning 合起来是一个名词短语,very 加 powerful 合起来是一个形容词短语,形容词短语加 is 以后会变成一个动词短语,动词短语加名词短语合起来是一个句子。
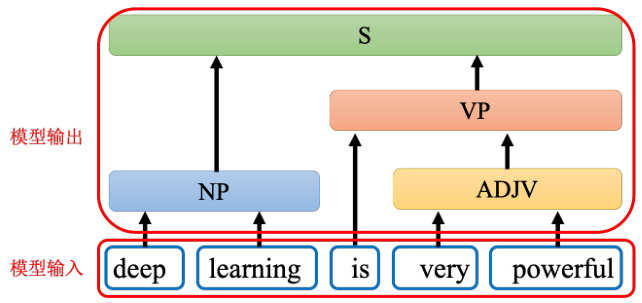
图 7.3 句法分析示例
在句法分析的任务中,输入是一段文字,输出是一个树状的结构,而一个树状的结构可以看成一个序列,该序列代表了这个树的结构,如图 7.4 所示。把树的结构转成一个序列以后,我们就可以用序列到序列模型来做句法分析,具体可参考论文“Grammar as a Foreign Language”
[1]。这篇论文放在 arXiv 上面的时间是 14 年的年底,当时序列到序列模型还不流行,其主要只有被用在翻译上。因此这篇论文的标题才会取“Grammar as a Foreign Language”,其把句法分析看成一个翻译的问题,把语法当作是另外一种语言直接套用。
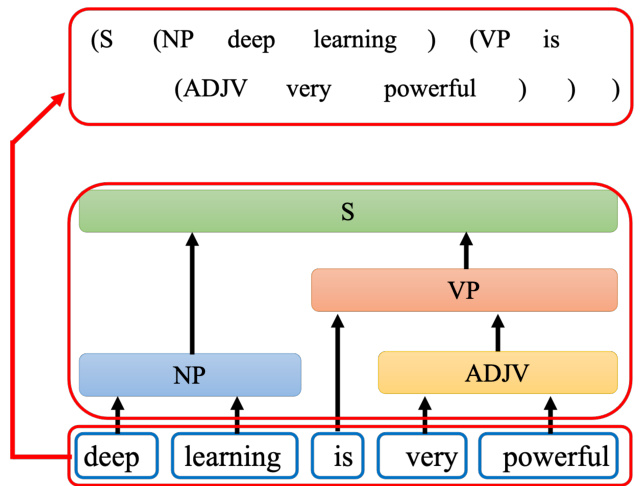
图 7.4 树状结构对应的序列
7.1.6 多标签分类
多标签分类(multi-label classification)任务也可以用序列到序列模型。多类的分类跟多标签的分类是不一样的。如图 7.5 所示,在做文章分类的时候,同一篇文章可能属于多个类,文章 1 属于类 1 和类 3,文章 3 属于类 3、9、17。
多分类问题(multi-class classification)是指分类的类别数大于 2。而多标签分类是指同一个东西可以属于多个类。

图 7.5 多标签分类示例
多标签分类问题不能直接把它当作一个多分类问题的问题来解。比如把这些文章丢到一个分类器里面,本来分类器只会输出分数最高的答案,如果直接取一个阈值(threshold),只输出分数最高的前三名。这种方法是不可行的,因为每篇文章对应的类别的数量根本不一样。因此需要用序列到序列模型来做,如图 7.6 所示,输入一篇文章,输出就是类别,机器决定输出类别的数量。这种看起来跟序列到序列模型无关的问题也可以用序列到序列模型解,比如目标检测问题也可以用序列到序列模型来做,读者可参考论文“End-to-End Object Detectionwith Transformers”[2]。

图 7.6 序列到序列模型来解多标签分类问题
7.2 Transformer 结构
一般的序列到序列模型会分成编码器和解码器,如图 7.7 所示。编码器负责处理输入的序列,再把处理好的结果“丢”给解码器,由解码器决定要输出的序列。
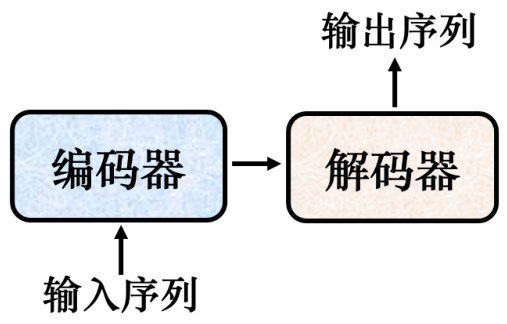
图 7.7 序列到序列模型结构
序列到序列模型的起源其实非常的早,在 14 年的 9 月就有一篇序列到序列模型用在翻译的论文:“Sequence to Sequence Learning with Neural Networks"3]。序列到序列典型的模型就是 Transformer,其有一个编码器架构和一个解码器架构,如图 7.8 所示。
7.3 Transformer 编码器
接下来介绍下 Transformer 的编码器。如图 7.9 所示,编码器输入一排向量,输出另外一排向量。自注意力、循环神经网络、卷积神经网络都能输入一排向量,输出一排向量。Transformer的编码器使用的是自注意力,输入一排向量,输出另外一个同样长度的向量。
如图 7.10 所示,编码器里面会分成很多的块(block),每一个块都是输入一排向量,输出一排向量。输入一排向量到第一个块,第一个块输出另外一排向量,以此类推,最后一个块会输出最终的向量序列。
Transformer 的编码器的每个块并不是神经网络的一层,每个块的结构如图 7.11 所示,在每个块里面,输入一排向量后做自注意力,考虑整个序列的信息,输出另外一排向量。接下来这排向量会“丢”到全连接网络网络里面,输出另外一排向量,这一排向量就是块的输出,事实上在原来的 Transformer 里面做的事情是更复杂的。
Transformer 里面加入了残差连接(residual connection)的设计,如图 7.12 所示,最左边的向量
批量归一化是对不同样本不同特征的同一个维度去计算均值跟标准差,但层归一化是对同一个特征、同一个样本里面不同的维度去计算均值跟标准差,接着做个归一化。输入向量
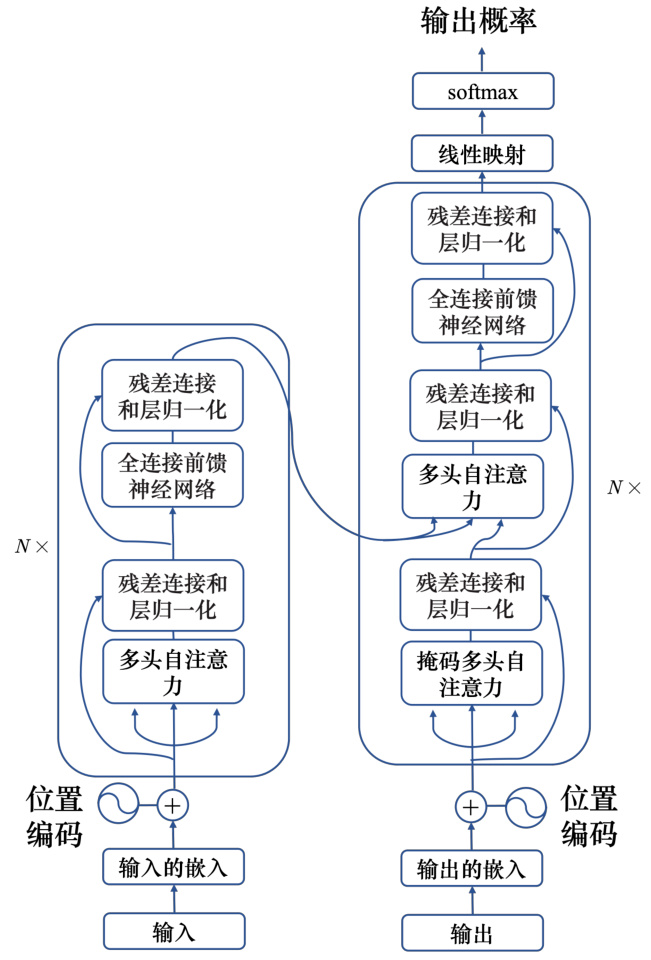
图 7.8 Transformer 结构
图 7.13 给出了 Transformer 的编码器结构,其中
Q: 为什么 Transformer 中使用层归一化,而不使用批量归一化?A: 论文“PowerNorm: Rethinking Batch Normalization in Transformers”解释了在Transformers 里面批量归一化不如层归一化的原因,并提出能量归一化(power nor-malization)。能量归一化跟层归一化性能差不多,甚至好一点。
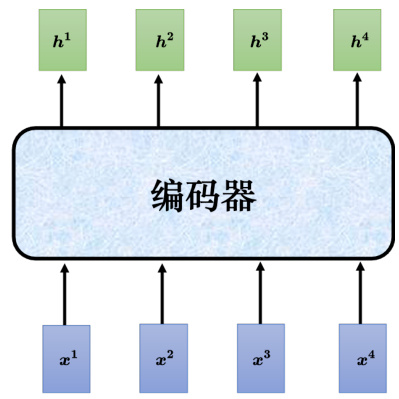
图 7.9 Transformer 编码器的功能
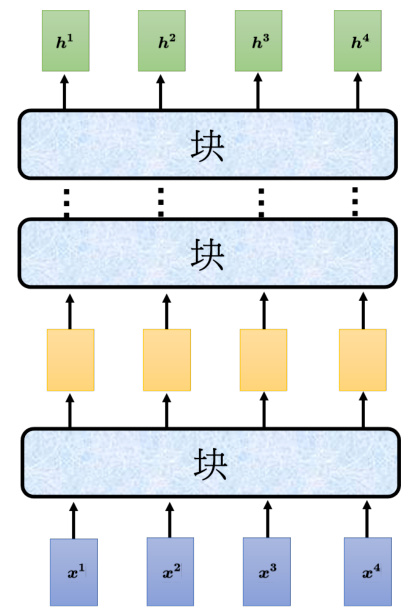
图 7.10 Transformer 编码器结构
7.4 Transformer 解码器
接下来介绍解码器,解码器比较常见的称为自回归的(autoregressive)解码器。
7.4.1 自回归解码器
以语音识别为例,输入一段声音,输出一串文字。如图 7.14 所示,把一段声音(“机器学习”)输入给编码器,输出会变成一排向量。接下来解码器产生语音识别的结果,解码器把编码器的输出先“读”进去。要让解码器产生输出,首先要先给它一个代表开始的特殊符号
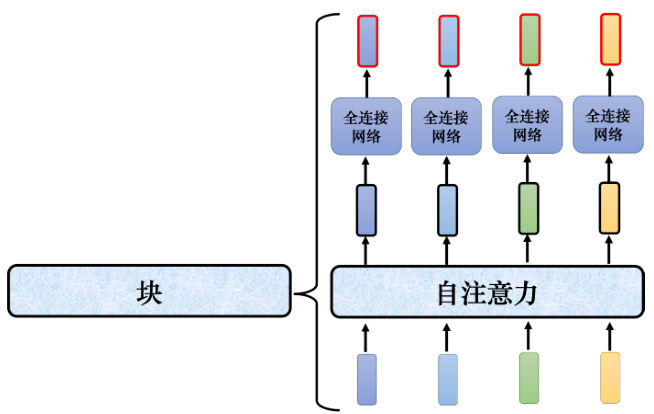
图 7.11 Transformer 编码器中每个块的结构
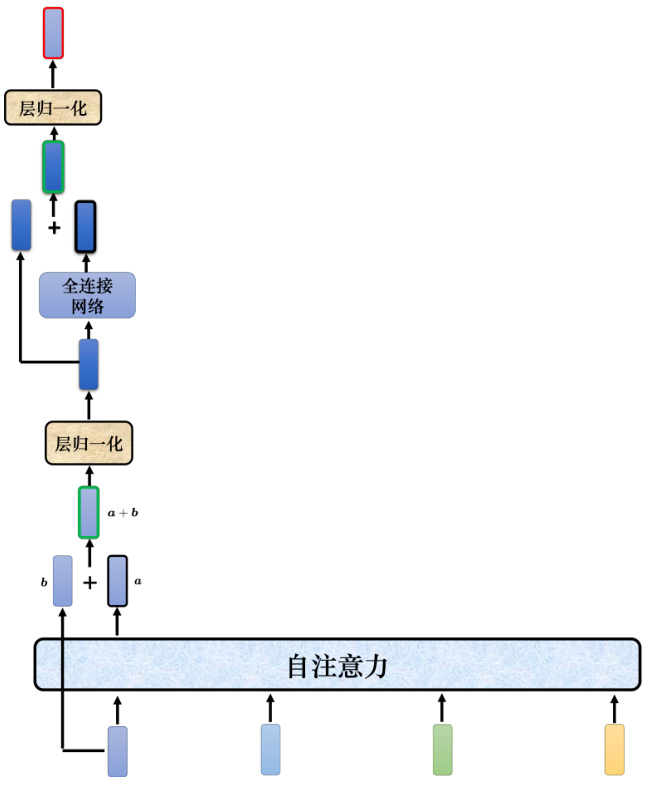
图 7.12 Transformer 中的残差连接
Q: 解码器输出的单位是什么?
A: 假设做的是中文的语音识别,解码器输出的是中文。词表的大小可能就是中文的方块字的数量。常用的中文的方块字大概两三千个,一般人可能认得的四、五千个,更多都是罕见字。比如我们觉得解码器能够输出常见的 3000 个方块字就好了,就把它列在词表中。不同的语言,输出的单位不见不会不一样,这取决于对语言的理解。比如英语,选择输出英语的字母。但字母作为单位可能太小了,有人可能会选择输出英语的词汇,英语的词汇是用空白作为间隔的。但如果都用词汇当作输出又太多了,有一些方法可以把英语的字首、字根切出来,拿字首、字根当作单位。中文通常用中文的方块字来当作单位,这个向量的长度就跟机器可以输出的方块字的数量是一样多的。每一个中文的字都会对应到一个数值。
如图 7.15 所示,接下来把“机”当成解码器新的输入。根据两个输入:特殊符号
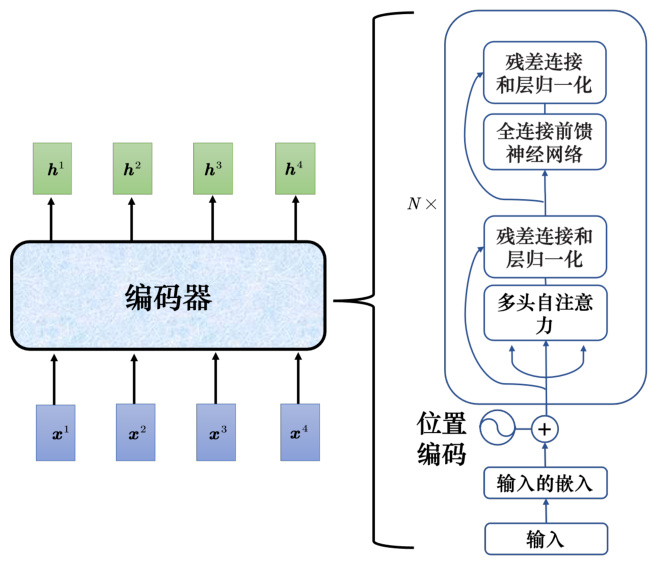
图 7.13 Transformer 编码器结构
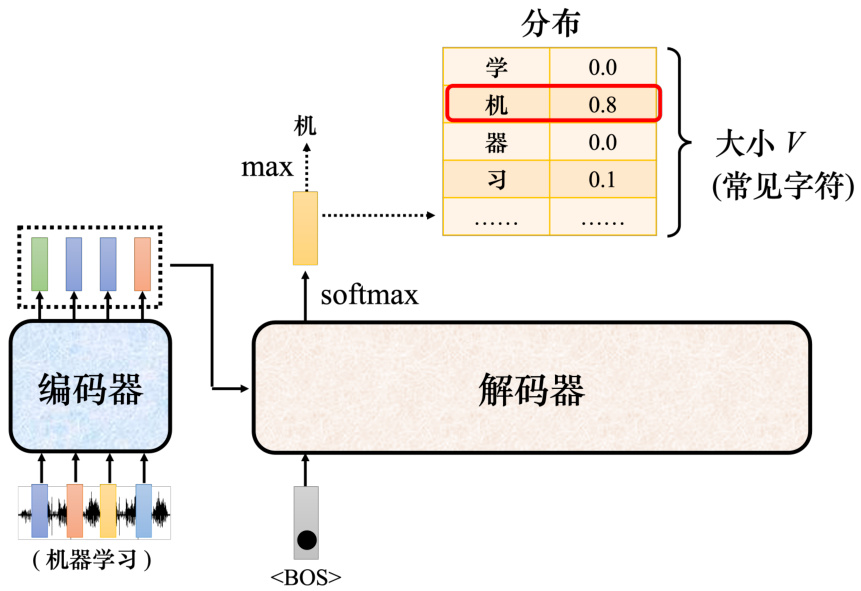
图 7.14 解码器的运作过程
解码器的输入是它在前一个时间点的输出,其会把自己的输出当做接下来的输入,因此当解码器在产生一个句子的时候,它有可能看到错误的东西。如图 7.16 所示,如果解码器有语音识别的错误,它把机器的“器”识别错成天气的“气”,接下来解码器会根据错误的识别结果产生它想要产生的期待是正确的输出,这会造成误差传播(error propagation)的问题,一步错导致步步错,接下来可能无法再产生正确的词汇。
Transformer 里面的解码器内部的结构如图 7.17 所示。类似于编码器,解码器也有多头注意力、残差连接和层归一化、前馈神经网络。解码器最后再做一个 softmax,使其输出变成一个概率。此外,解码器使用了掩蔽自注意力(masked self-attention),掩蔽自注意力可以通过一个掩码(mask)来阻止每个位置选择其后面的输入信息。
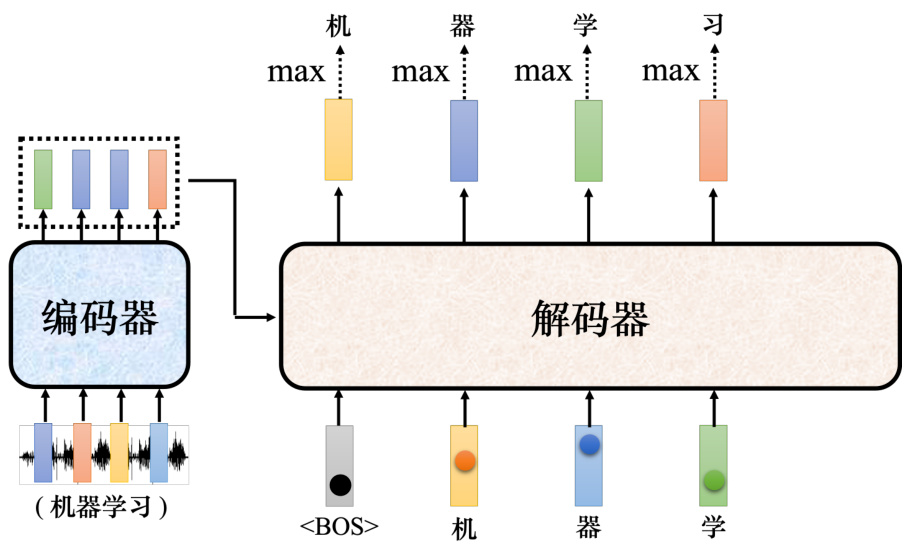
图 7.15 解码器示例
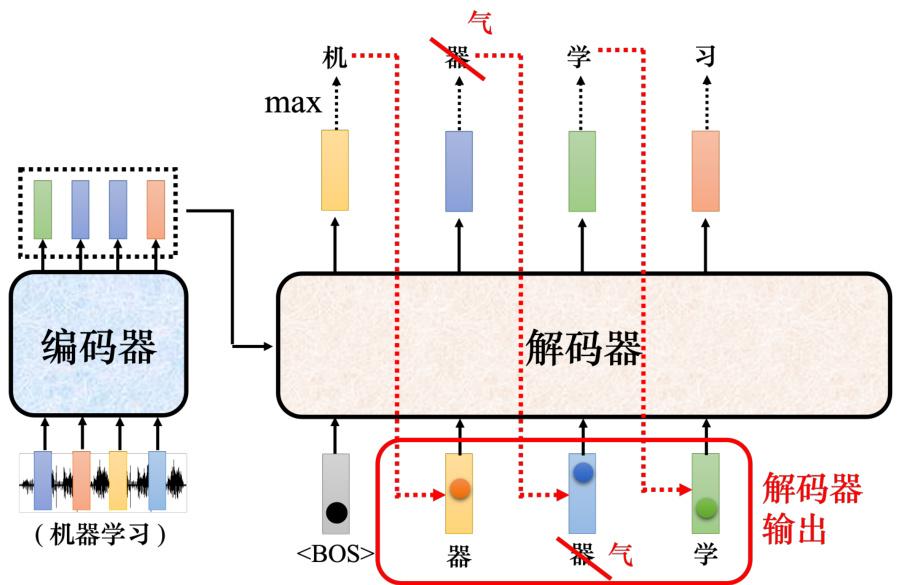
图 7.16 解码器中的误差传播
如图 7.18 所示,原来的自注意力输入一排向量,输出另外一排向量,这一排中每个向量都要看过完整的输入以后才做决定。根据
一般自注意力产生
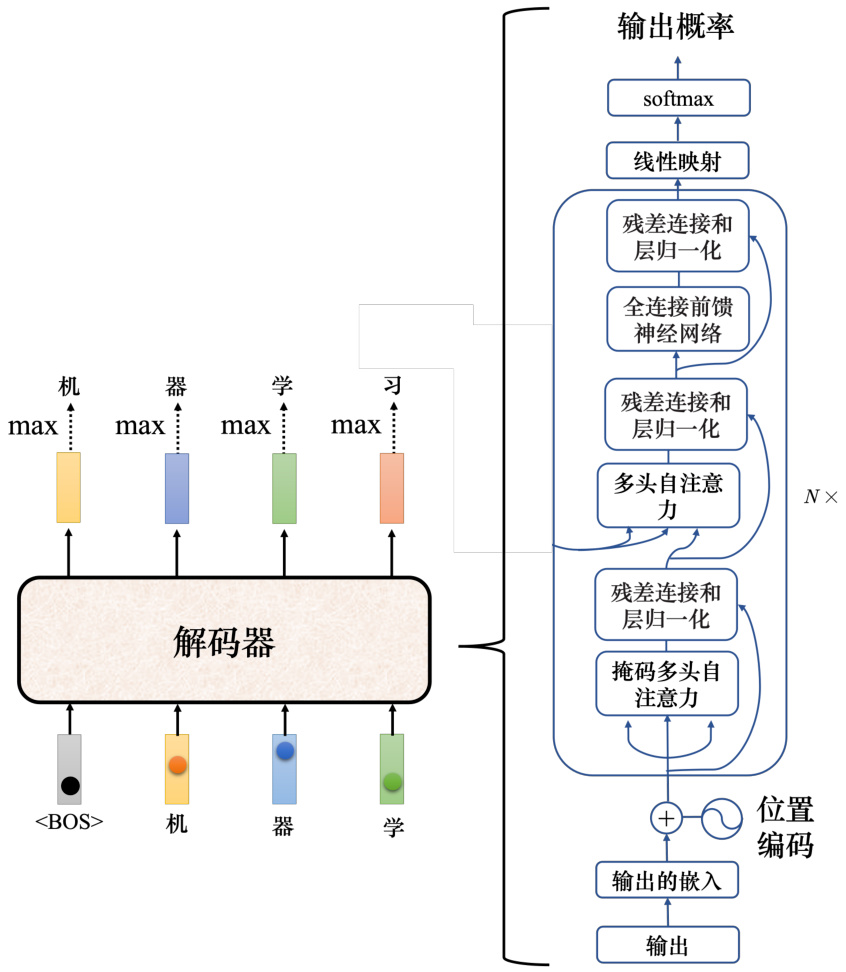
图 7.17 解码器内部结构
Q: 为什么需要在注意力中加掩码?
A: 一开始解码器的输出是一个一个产生的,所以是先有 ${\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf{}}{\mathbf}{}{\mathbf}{}{\mathbf}{\mathbf{}}{\mathbf{}}{\mathbf}{}{\mathbf}{\mathbf{}}{\mathbf}{}{\mathbf}{\mathbf{}}{\mathbf}{}{\mathbf}{}{\mathbf}{\mathbf}{}{\mathbf}{}{\mathbf}{\mathbf}{}{\mathbf}{}{\mathbf}{}{\mathbf}{}{\mathbf}{}{\mathbf}{}{\mathbf}{}{\mathbf}{}{\mathbf}{}{\mathbf}{}{\mathbf}{}{\mathbf}{}{\mathbf}{}{}{\mathbf}{}{\mathbf}{}{}{\mathbf}{}{}{\mathbf}{}{}{\mathbf}{}{}{\mathbf}{}{}{\mathbf}{}{}{}{\mathbf}{}{}{}{\mathbf}{}{}{}{\mathbf}{}{}{}{}{\mathbf}{}{}{}{}{\mathbf}{}{}{}{}{}{}{\mathbf}{}{}{}{}{}{}{}{}{\mathbf}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{}{} $ 再有
了解了解码器的运作方式,但这还有一个非常关键的问题:实际应用中输入跟输出长度的关系是非常复杂的,我们无法从输入序列的长度知道输出序列的长度,因此解码器必须决定输出的序列的长度。给定一个输入序列,机器可以自己学到输出序列的长度。但在目前的解码器运作的机制里面,机器不知道什么时候应该停下来,如图 7.22 所示,机器产生完“习”以后,还可以继续重复一模一样的过程,把“习”当做输入,解码器可能就会输出“惯”,接下来就一直持续下去,永远都不会停下来。
如图 7.23 所示,要让解码器停止运作,需要特别准备一个特别的符号
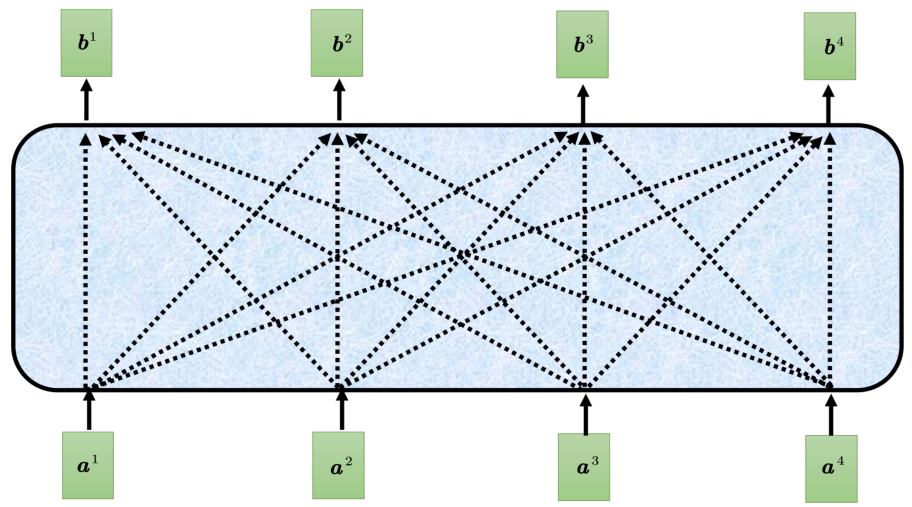
图 7.18 一般的自注意力示例
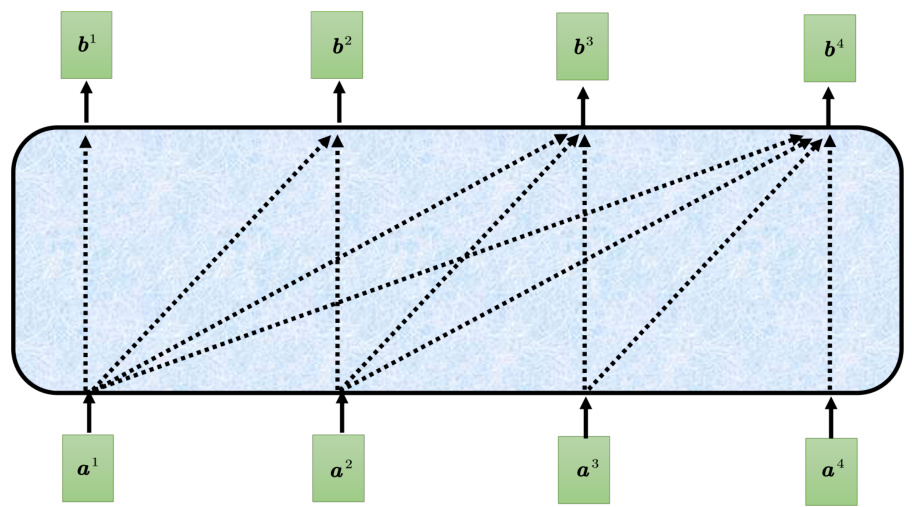
图 7.19 掩蔽自注意力示例
7.4.2 非自回归解码器
接下来讲下非自回归(non-autoregressive)的模型。如图 7.24 所示,自回归的模型是先输入
• 用分类器来解决这个问题。用分类器“吃”编码器的输入,输出是一个数字,该数字代表解码器应该要输出的长度。比如分类器输出 4,非自回归的解码器就会“吃”4 个
• 给编码器一堆
非自回归的解码器有很多优点。第一个优点是平行化。自回归的解码器输出句子的时候是一个一个字产生的,假设要输出长度一百个字的句子,就需要做一百次的解码。但是非自回归的解码器不管句子的长度如何,都是一个步骤就产生出完整的句子。所以非自回归的解码器会跑得比自回归的解码器要快。非自回归解码器的想法是在有 Transformer 以后,有这种自注意力的解码器以后才有的。以前如果用长短期记忆网络(Long Short-Term Memory Network,LSTM)或 RNN,给它一排
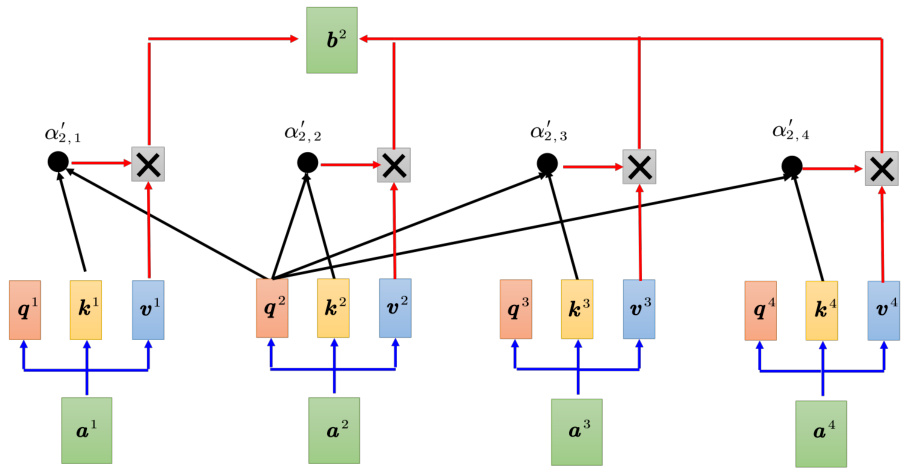
图 7.20 一般自注意力具体计算过程
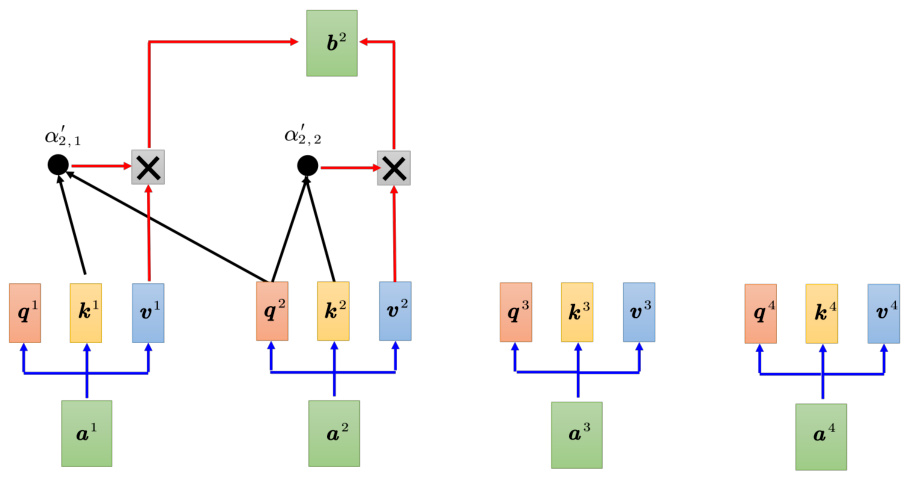
图 7.21 掩蔽自注意力具体计算过程
另外一个优点是非自回归的解码器比较能够控制它输出的长度。在语音合成里面,非自回归解码器算是非常常用的。非自回归的解码器可以控制输出的长度,可以用一个分类器决定非自回归的解码器应该输出的长度。在做语音合成的时候,如果想要让系统讲快一点,就把分类器的输出除以 2,系统讲话速度就变 2 倍快。如果想要讲话放慢速度,就把分类器输出的长度乘 2 倍,解码器说话的速度就变 2 倍慢。因此非自回归的解码器可以控制解码器输出的长度,做出种种的变化。
平行化是非自回归解码器最大的优势,但非自回归的解码器的性能(performance)往往都不如自回归的解码器。所以很多研究试图让非自回归的解码器的性能越来越好,去逼近自回归的解码器。要让非自回归的解码器跟自回归的解码器性能一样好,必须要使用非常多的技巧。
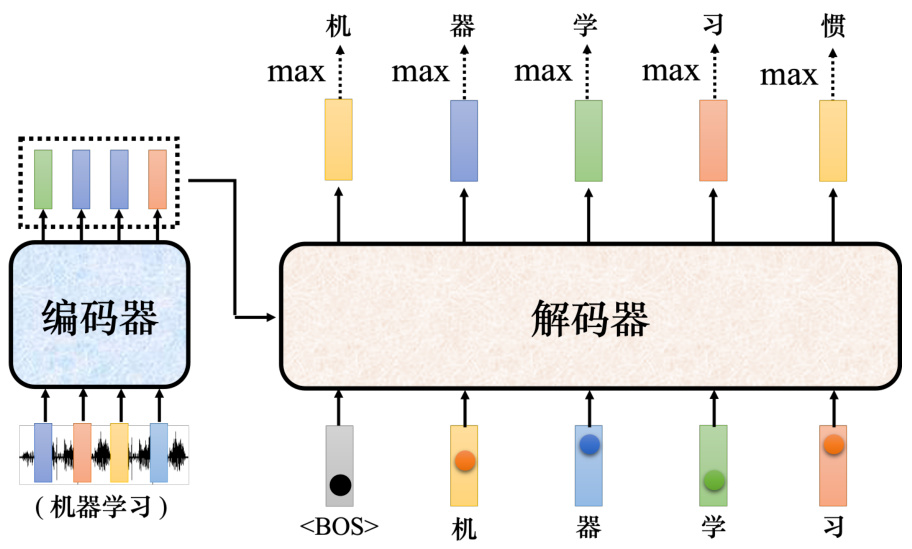
图 7.22 解码器运作的问题
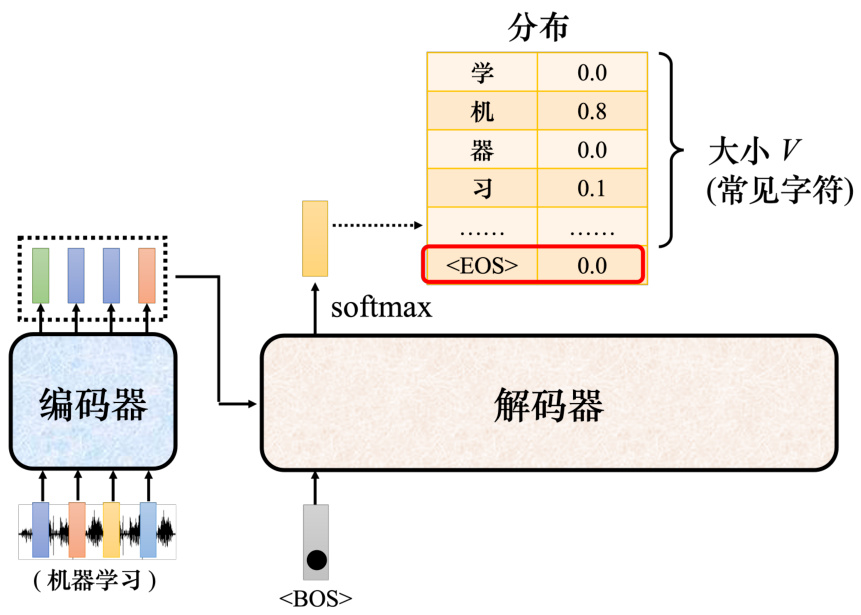
图 7.23 添加
7.5 编码器-解码器注意力
编码器和解码器通过编码器-解码器注意力(encoder-decoder attention)传递信息,编码器-解码器注意力是连接编码器跟解码器之间的桥梁。如图 7.25 所示,解码器中编码器-解码器注意力的键和值来自编码器的输出,查询来自解码器中前一个层的输出。
接下来介绍下编码器-解码器注意力实际的运作过程。如图 7.26 所示,编码器输入一排向量,输出一排向量
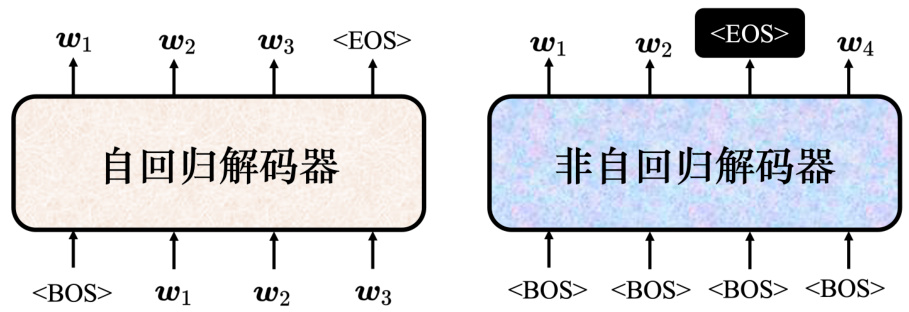
图 7.24 自回归解码器与非自回归解码器对比
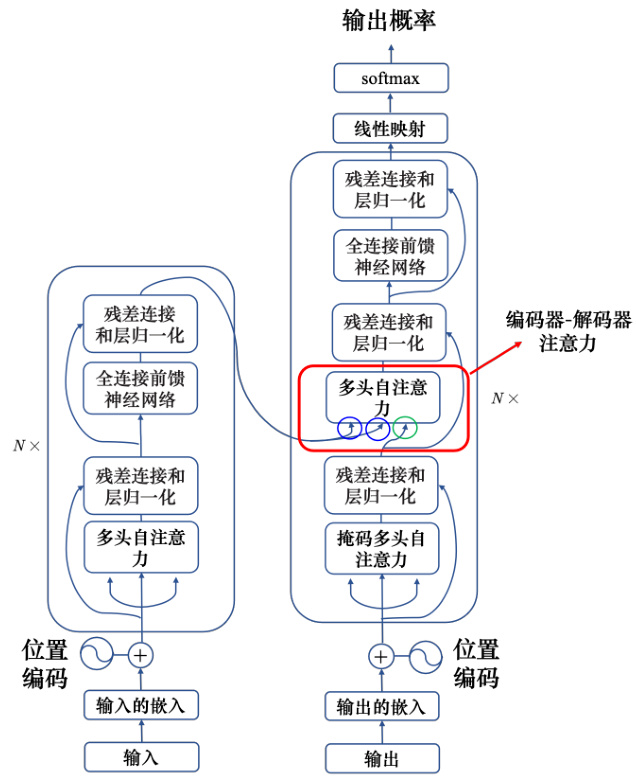
图 7.25 编码器-解码器注意力
如图 7.27 所示,假设产生“机”,输入
编码器和解码器都有很多层,但在原始论文中解码器是拿编码器最后一层的输出。但不 一定要这样,读者可参考论文“Rethinking and Improving Natural Language Generation with Layer-Wise Multi-View Decoding”[4]。
7.6 Transformer 的训练过程
如图 7.28 所示,Transformer 应该要学到听到“机器学习”的声音信号,它的输出就是“机器学习”这四个中文字。把 <BOS
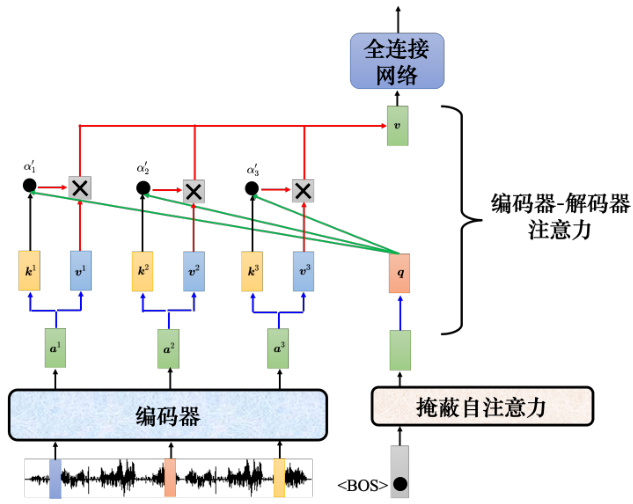
图 7.26 编码器-解码器注意力运作过程
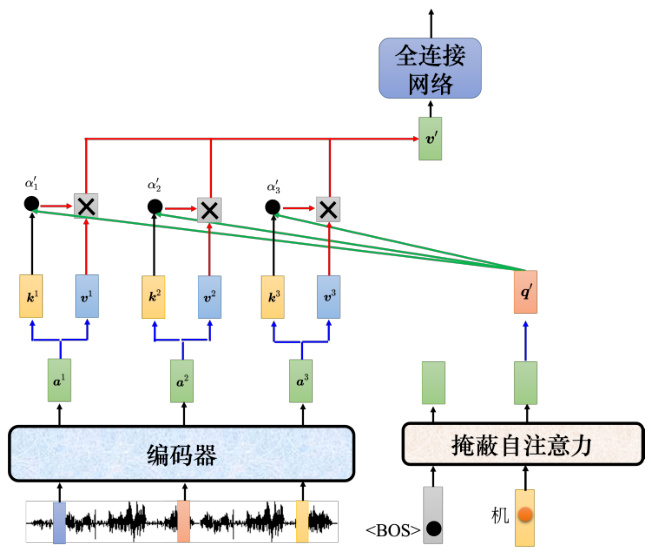
图 7.27 编码器-解码器注意力运作过程示例
如图 7.29 所示,实际训练的时候,输出应该是“机器学习”。解码器第一次的输出、第二次的输出、第三次的输出、第四次输出应该分别就是“机”“器”“学”“习"这四个中文字的独热向量,输出跟这四个字的独热向量越接近越好。在训练的时候,每一个输出跟其对应的正确答案都有一个交叉熵。图 7.29 中做了四次分类问题,希望这些分类的问题交叉熵总和越小越好。训练的时候,解码器输出的不是只有“机器学习”这四个中文字,还要输出
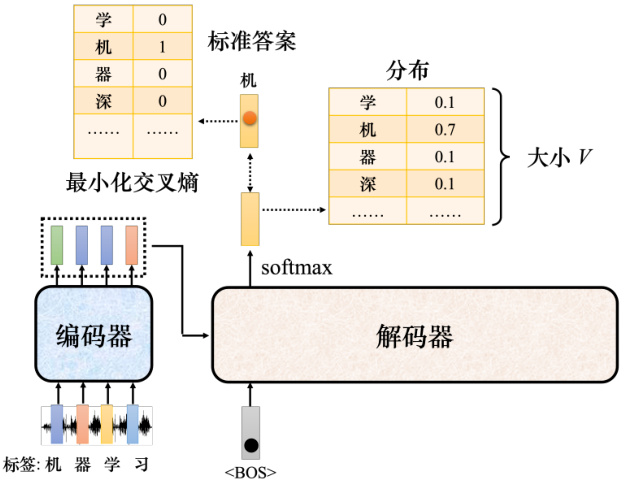
图 7.28 Transformer 的训练过程
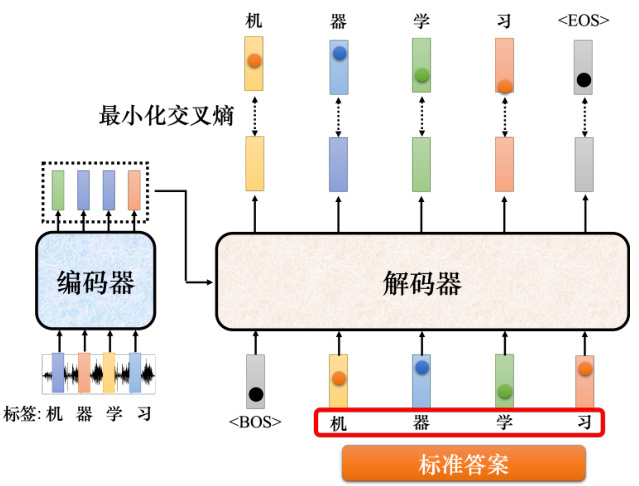
图 7.29 教师强制
7.7 序列到序列模型训练常用技巧
接下来介绍下训练序列到序列模型的一些技巧。
7.7.1 复制机制
第一个技巧是复制机制(copy mechanism)。对很多任务而言,解码器没有必要自己创造输出,其可以从输入的东西里面复制一些东西。以聊天机器人为例,用户对机器说:“你好,我是库洛洛”。机器应该回答:“库洛洛你好,很高兴认识你”。机器其实没有必要创造“库洛洛”这个词汇,“库洛洛”对机器来说一定会是一个非常怪异的词汇,所以它可能很难在训练数据里面出现,可能一次也没有出现过,所以它不太可能正确地产生输出。但是假设机器在学的时候,学到的并不是它要产生“库洛洛”,它学到的是看到输入的时候说“我是某某某”,就直接把“某某某”复制出来,说“某某某你好”。这种机器的训练会比较容易,显然比较有可能得到正确的结果,所以复制对于对话任务可能是一个需要的技术。机器只要复述这一段它听不懂的话,它不需要从头去创造这一段文字,它要学的是从用户的输入去复制一些词汇当做输出。
在做摘要的时候,我们可能更需要复制的技巧。做摘要需要搜集大量的文章,每一篇文章都有人写的摘要,训练一个序列到序列的模型就结束了。要训练机器产生合理的句子,通常需要百万篇文章,这些文章都要有人标的摘要。在做摘要的时候,很多的词汇就是直接从原来的文章里面复制出来的,所以对摘要任务而言,从文章里面直接复制一些信息出来是一个很关键的能力,最早有从输入复制东西的能力的模型叫做指针网络(pointer network),后来还有一个变形叫做复制网络(copy network)。
7.7.2 引导注意力
序列到序列模型有时候训练出来会产生莫名其妙的结果。以语音合成为例,机器念 4 次的“发财”,重复 4 次没问题,但叫它只念一次“发财”,它把“发”省略掉只念“财”。也许在训练数据里面,这种非常短的句子很少,所以机器无法处理这种非常短的句子。这个例子并没有常出现,用序列到序列学习出来,语音合成没有这么差。类似于语音识别、语音合成这种任务最适合使用引导注意力。因为像语音识别,很难接受,我们讲一句话,识别出来居然有一段机器没听到。或者像语音合成这种任务,输入一段文字,语音合出来居然有一段没有念到。引导注意力要求机器在做注意力的时候有固定的方式。对语音合成或语音识别,我们想像中的注意力应该就是由左向右。如图 7.30 所示,红色的曲线来代表注意力的分数,越高就代表注意力的值越大。以语音合成为例,输入就是一串文字,合成声音的时候,显然是由左念到右。所以机器应该是先看最左边输入的词汇产生声音,再看中间的词汇产生声音,再看右边的词汇产生声音。如果做语音合成的时候,机器的注意力是颠三倒四的,它先看最后面,接下来再看前面,再胡乱看整个句子,显然这样的注意力是有问题的,没有办法合出好的结果。因此引导注意力会强迫注意力有一个固定的样貌,如果我们对这个问题本身就已经有理解,知道对于语音合成这样的问题,注意力的位置都应该由左向右,不如就直接把这个限制放进训练里面,要求机器学到注意力就应该要由左向右。
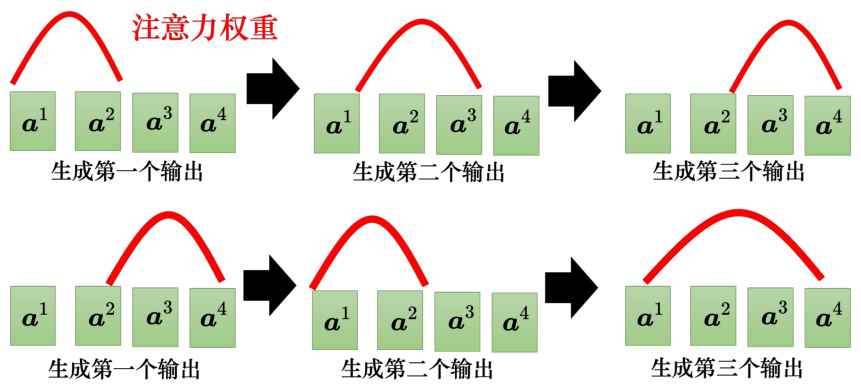
图 7.30 引导注意力
7.7.3 束搜索
如图 7.31 所示,假设解码器就只能产生两个字 A 和 B,假如世界上只有两个字 A 跟 B,即词表
但贪心搜索不一定是最好的方法,第一步可以先稍微舍弃一点东西,第一步虽然 B 是 0.4,但先选 B。选了 B,第二步时 B 的可能性就大增就变成 0.9。到第三步时,B 的可能性也是0.9。绿色路径虽然第一步选了一个较差的输出,但是接下来的结果是好的。比较下红色路径与绿色路径,红色路径第一步好,但全部乘起来是比较差的,绿色路径一开始比较差,但最终结果其实是比较好的。
如何找到最好的结果是一个值得考虑的问题。穷举搜索(exhaustive search)是最容易想到的方法,但实际上并没有办法穷举所有可能的路径,因为每一个转折点的选择太多了。对中文而言,中文有 4000 个字,所以树每一个地方的分叉都是 4000 个可能的路径,走两三步以后,就会无法穷举。
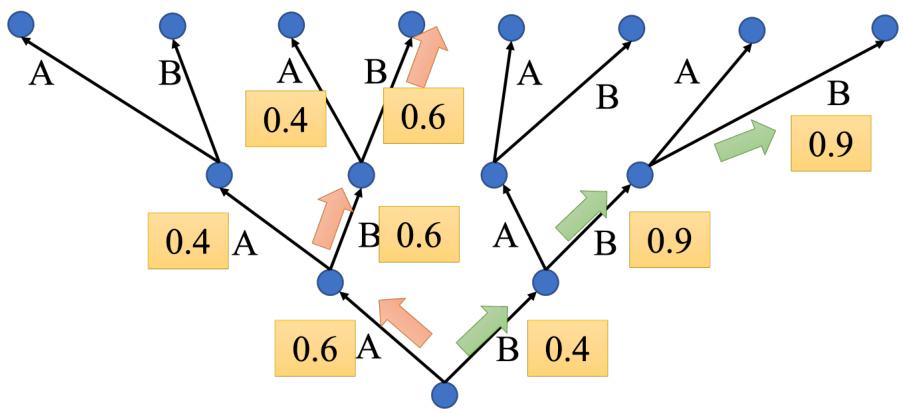
图 7.31 解码器搜索示例
接下来介绍下束搜索(beam search),束搜索经常也称为集束搜索或柱搜索。束搜索是用比较有效的方法找一个近似解,在某些情况下效果不好。比如论文“The Curious Case OfNeuralText Degeneration"[5]。这个任务要做的事情是完成句子(sentence completion),也就是机器先读一段句子,接下来它要把这个句子的后半段完成,如果用束搜索,会发现说机器不断讲重复的话。如果不用束搜索,加一些随机性,虽然结果不一定完全好,但是看起来至少是比较正常的句子。有时候对解码器来说,没有找出分数最高的路,反而结果是比较好的,这个就是要看任务本身的特性。假设任务的答案非常明确,比如语音识别,说一句话,识别的结果就只有一个可能。对这种任务而言,通常束搜索就会比较有帮助。但如果任务需要机器发挥一点创造力,束搜索比较没有帮助。
7.7.4 加入噪声
在做语音合成的时候,解码器加噪声,这是完全违背正常的机器学习的做法。在训练的时候会加噪声,让机器看过更多不同的可能性,这会让模型比较鲁棒,比较能够对抗它在测试的时候没有看过的状况。但在测试的时候居然还要加一些噪声,这不是把测试的状况弄得更困难,结果更差。但语音合成神奇的地方是,模型训练好以后。测试的时候要加入一些噪声,合出来的声音才会好。用正常的解码的方法产生出来的声音听不太出来是人声,产生出比较好的声音是需要一些随机性的。对于语音合成或句子完成任务,解码器找出最好的结果不一定是人类觉得最好的结果,反而是奇怪的结果,加入一些随机性的结果反而会是比较好的。
7.7.5 使用强化学习训练
接下来还有另外一个问题,我们评估的标准用的是 BLEU(BiLingual Evaluation Under-study)分数。虽然 BLEU 最先是用于评估机器翻译的结果,但现在它已经被广泛用于评价许多应用输出序列的质量。解码器先产生一个完整的句子,再去跟正确的答案一整句做比较,拿两个句子之间做比较算出 BLEU 分数。但训练的时候,每一个词汇是分开考虑的,最小化的是交叉熵,最小化交叉熵不一定可以最大化 BLEU 分数。但在做验证的时候,并不是挑交叉熵最低的模型,而是挑 BLEU 分数最高的模型。一种可能的想法:训练的损失设置成 BLEU分数乘一个负号,最小化损失等价于最大化 BLEU 分数。但 BLEU 分数很复杂,如果要计算两个句子之间的 BLEU 分数,损失根本无法做微分。我们之所以采用交叉熵,而且是每一个中文的字分开来算,就是因为这样才有办法处理。遇到优化无法解决的问题,可以用强化学习训练。具体来讲,遇到无法优化的损失函数,把损失函数当成强化学习的奖励,把解码器当成智能体,可参考论文“Sequence Level Training with Recurrent Neural Networks”。
7.7.6 计划采样
如图 7.32 所示,测试的时候,解码器看到的是自己的输出,因此它会看到一些错误的东西。但是在训练的时候,解码器看到的是完全正确的,这种不一致的现象叫做曝光偏差(exposurebias)。
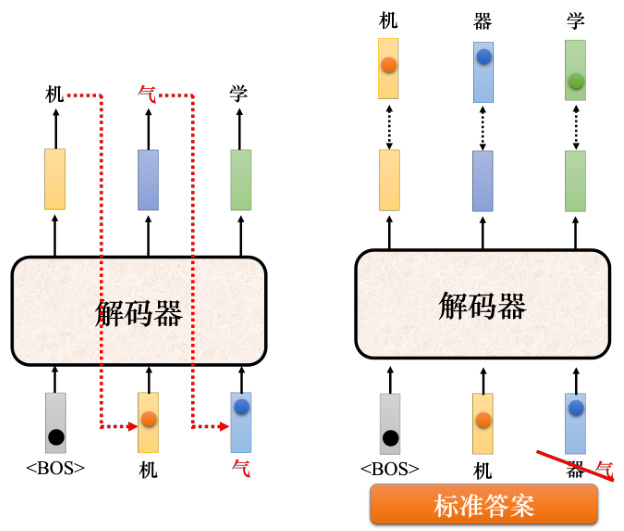
图 7.32 曝光偏差
假设解码器在训练的时候永远只看过正确的东西,在测试的时候,只要有一个错,就会一步错步步错。因为解码器从来没有看过错的东西,它看到错的东西会非常的惊奇,接下来它产生的结果可能都会错掉。有一个可以的思考的方向是:给解码器的输入加一些错误的东西,不要给解码器都是正确的答案,偶尔给它一些错的东西,它反而会学得更好,这一技巧称为计划采样(scheduled sampling)[6],它不是学习率调整(schedule learning rate)。很早就有计划采样,在还没有 Transformer、只有 LSTM 的时候,就已经有计划采样。但是计划采样会伤害到 Transformer 的平行化的能力,所以 Transformer 的计划采样另有招数,其跟原来最早提在这个 LSTM 上被提出来的招数也不太一样。读者可参考论文“Scheduled Sampling forTransformers”[7]、“Parallel Scheduled Sampling”[8]。
参考文献
[1] VINYALS O, KAISER Ł, KOO T, et al. Grammar as a foreign language[J]. Advances in neural information processing systems, 2015, 28.
[2] CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers[C]//European conference on computer vision. Springer, 2020: 213-229.
[3] SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks[J]. Advances in neural information processing systems, 2014, 27.
[4] LIU F, REN X, ZHAO G, et al. Rethinking and improving natural language generation with layer-wise multi-view decoding[J]. arXiv preprint arXiv:2005.08081, 2020.
[5] HOLTZMAN A, BUYS J, DU L, et al. The curious case of neural text degeneration[J]. arXiv preprint arXiv:1904.09751, 2019.
[6] BENGIO S, VINYALS O, JAITLY N, et al. Scheduled sampling for sequence prediction with recurrent neural networks[C]//volume 28. 2015.
[7] MIHAYLOVA T, MARTINS A F. Scheduled sampling for transformers[J]. arXiv preprint arXiv:1906.07651, 2019.
[8] DUCKWORTH D, NEELAKANTAN A, GOODRICH B, et al. Parallel scheduled sampling[J]. arXiv preprint arXiv:1906.04331, 2019.